This is the full developer documentation for KARMA OpenMedEvalKit
# KARMA-OpenMedEvalKit
> Knowledge Assessment and Reasoning for Medical Applications - An evaluation framework for medical AI models.
## Why KARMA?
[Section titled “Why KARMA?”](#why-karma)
KARMA is designed for researchers, developers, and healthcare organizations who need reliable evaluation of medical AI systems.
Extensible
Bring your own model, dataset or even metric. Integrated with Huggingface and also supports local evaluation.
[Add your own →](/user-guide/add-your-own/add-model/)
Fast & Efficient
Process thousands of medical examples efficiently with intelligent caching and batch processing.
[See caching →](/caching)
Multi-Modal Ready
Support for text, images, and audio evaluation across multiple datasets.
[See available datasets →](/user-guide/datasets/datasets_overview)
Model Agnostic
Works with any model - Qwen, MedGemma, Bedrock-SDK, OpenAI-SDK or your custom architecture with unified interface.
[See available models →](/user-guide/models/built-in-models/)
## Quick Start
[Section titled “Quick Start”](#quick-start)
Get started with KARMA in minutes:
```bash
# Install KARMA
pip install karma-medeval
# Run your first evaluation
karma eval --model "Qwen/Qwen3-0.6B" --datasets openlifescienceai/pubmedqa --max-samples 3
```
## Example Output
[Section titled “Example Output”](#example-output)
```bash
$ karma eval --model "Qwen/Qwen3-0.6B" --datasets openlifescienceai/pubmedqa --max-samples 3
{
"openlifescienceai/pubmedqa": {
"metrics": {
"exact_match": {
"score": 0.3333333333333333,
"evaluation_time": 0.9702351093292236,
"num_samples": 3
}
},
"task_type": "mcqa",
"status": "completed",
"dataset_args": {},
"evaluation_time": 7.378399848937988
},
"_summary": {
"model": "Qwen/Qwen3-0.6B",
"model_path": "Qwen/Qwen3-0.6B",
"total_datasets": 1,
"successful_datasets": 1,
"total_evaluation_time": 7.380354166030884,
"timestamp": "2025-07-22 18:43:07"
}
}
```
## Key Features
[Section titled “Key Features”](#key-features)
* **Registry-Based Architecture**: Auto-discovery of models, datasets, and metrics
* **Smart Caching**: DuckDB and DynamoDB backends for faster re-evaluations
* **Extensible Design**: Easy integration of custom models, datasets, and metrics
* **Rich CLI**: Beautiful progress bars, formatted outputs, and help
* **Standards-Based**: Built on PyTorch and HuggingFace Transformers
## Getting Started
[Section titled “Getting Started”](#getting-started)
Installation
Multiple installation methods with uv, pip, or development setup.
[Install KARMA →](/user-guide/installation/)
Basic Usage
Learn the CLI commands and start evaluating your first model.
[Learn CLI →](/user-guide/cli-basics/)
Add Your Own
Extend KARMA with custom models, datasets, and evaluation metrics.
[Customize →](/user-guide/add-your-own/add-model/)
Supported Resources
Complete list of available models, datasets, and metrics.
[View Resources →](/supported-resources/)
## Release resources
[Section titled “Release resources”](#release-resources)
[KARMA release blog ](http://info.eka.care/services/introducing-karma-openmedevalkit-an-open-source-framework-for-medical-ai-evaluation)Read about KARMA
[4 novel healthcare datasets ](< http://info.eka.care/services/advancing-healthcare-ai-evaluation-in-india-ekacare-releases-four-evaluation-datasets>)Read about the datasets released along with KARMA
[Beyond WER - SemWER ](http://info.eka.care/services/beyond-traditional-wer-the-critical-need-for-semantic-wer-in-asr-for-indian-healthcare)Read about the two new metrics introduced in KARMA for ASR
Ready to evaluate your medical AI models? [Get started with installation →](/user-guide/installation/)
# Core Components of KARMA
This document defines the four core components of KARMA’s evaluation system and how they interact with each other.
1. Models
2. Datasets
3. Metrics
4. Processors
## Data Flow Sequence
[Section titled “Data Flow Sequence”](#data-flow-sequence)
```
sequenceDiagram
participant CLI
participant Orchestrator
participant Registry
participant Model
participant Dataset
participant Processor
participant Metrics
participant Cache
CLI->>Orchestrator: karma eval model --datasets ds1
Orchestrator->>Registry: discover_all_registries()
Registry-->>Orchestrator: components metadata
Orchestrator->>Model: initialize with config
Orchestrator->>Dataset: initialize with args
Orchestrator->>Processor: initialize processors
loop For each dataset
Orchestrator->>Dataset: create dataset instance
Dataset->>Processor: apply postprocessors
loop For each batch
Dataset->>Model: provide samples
Model->>Cache: check cache
alt Cache miss
Model->>Model: run inference
Model->>Cache: store results
end
Model-->>Dataset: return predictions
Dataset->>Dataset: extract_prediction()
Dataset->>Processor: postprocess predictions
Processor-->>Dataset: processed text
Dataset->>Metrics: evaluate(predictions, references)
Metrics-->>Dataset: scores
end
Dataset-->>Orchestrator: evaluation results
end
Orchestrator-->>CLI: aggregated results
```
## Component Interaction Diagram
[Section titled “Component Interaction Diagram”](#component-interaction-diagram)
```
graph TD
%% CLI Layer
CLI[CLI Command
karma eval model --datasets ds1,ds2]
%% Orchestrator Layer
ORCH[Orchestrator
MultiDatasetOrchestrator]
%% Registry System
MR[Model Registry]
DR[Dataset Registry]
MetR[Metrics Registry]
PR[Processor Registry]
%% Core Components
MODEL[Model
BaseModel]
DATASET[Dataset
BaseMultimodalDataset]
METRICS[Metrics
BaseMetric]
PROC[Processors
BaseProcessor]
%% Benchmark
BENCH[Benchmark
Evaluation Engine]
%% Cache System
CACHE[Cache Manager
DuckDB/DynamoDB]
%% Data Flow
CLI --> |parse args| ORCH
ORCH --> |discover| MR
ORCH --> |discover| DR
ORCH --> |discover| MetR
ORCH --> |discover| PR
MR --> |create| MODEL
DR --> |create| DATASET
MetR --> |create| METRICS
PR --> |create| PROC
ORCH --> |orchestrate| BENCH
BENCH --> |inference| MODEL
BENCH --> |iterate| DATASET
BENCH --> |compute| METRICS
BENCH --> |cache lookup/store| CACHE
DATASET --> |postprocess| PROC
DATASET --> |extract predictions| MODEL
MODEL --> |predictions| DATASET
DATASET --> |processed data| METRICS
PROC --> |normalized text| METRICS
%% Configuration Flow
CLI -.-> |--model-args| MODEL
CLI -.-> |--dataset-args| DATASET
CLI -.-> |--metric-args| METRICS
CLI -.-> |--processor-args| PROC
%% Styling
classDef cli fill:#e1f5fe
classDef orchestrator fill:#f3e5f5
classDef registry fill:#fff3e0
classDef component fill:#e8f5e8
classDef benchmark fill:#fff8e1
classDef cache fill:#fce4ec
class CLI cli
class ORCH orchestrator
class MR,DR,MetR,PR registry
class MODEL,DATASET,METRICS,PROC component
class BENCH benchmark
class CACHE cache
```
This architecture ensures clean separation of concerns while enabling flexible configuration and robust error handling throughout the evaluation process.
# Sanity benchmark
To ensure that we have implemented the datasets loading, model invocation and metric calculation correctly, we have invoked the model and have reproduced numbers.
## MedGemma-4B Reproduction
[Section titled “MedGemma-4B Reproduction”](#medgemma-4b-reproduction)
In case of Medgemma, we have been able to reproduce the results for most datasets as claimed in their technical report and huggingface readme page.
# Use KARMA with an LLM
Navigate to [llms-full.txt](https://karma.eka.care/llms-full.txt), copy the documentation from there and paste into your LLM and ask questions.
The llms.txt file has been generated based on these docs and found it to work reliably with claude.
# Caching
KARMA saves the model’s predictions locally to avoid redundant computations. This ensures that running multiple metrics or extending datasets is trivial.
## How are items cached?
[Section titled “How are items cached?”](#how-are-items-cached)
KARMA caches at a sample level for each evaluated model + configuration and dataset combinations. For example, if we run evalution on pubmedqa with the Qwen3-0.6B model, we will cache for each of the configurations. So if temperature is changed and evalution is run once again, then model will be invoked again. However, if only a new metric has been added along with exact\_match on the dataset, then the cached model outputs are reused.
Caching is hugely beneficial for ASR related models as well since the metric computation also evolves over time. For example, if we run evaluation on a dataset with a new metric, the cached model outputs are reused.
## DuckDB Caching
[Section titled “DuckDB Caching”](#duckdb-caching)
DuckDB is a lightweight, in-memory, columnar database that is used by KARMA to cache the model’s predictions. This the default way of caching.
## DynamoDB Caching
[Section titled “DynamoDB Caching”](#dynamodb-caching)
DynamoDB is a NoSQL database service provided by Amazon Web Services (AWS). KARMA can also use DynamoDB to cache model predictions. This is useful for large-scale deployments where the model predictions need to be stored in a highly scalable and durable manner.
To use DynamoDB caching, you need to configure the following environment variables:
* `AWS_ACCESS_KEY_ID`: Your AWS access key ID.
* `AWS_SECRET_ACCESS_KEY`: Your AWS secret access key.
* `AWS_REGION`: The AWS region where your DynamoDB table is located.
Once you have configured these environment variables, you can enable DynamoDB caching by setting the `KARMA_CACHE_TYPE` environment variable to `dynamodb`.
# karma eval
> Complete reference for the karma eval command
The `karma eval` command is the core of KARMA, used to evaluate models on healthcare datasets.
## Usage
[Section titled “Usage”](#usage)
```bash
karma eval [OPTIONS]
```
## Description
[Section titled “Description”](#description)
Evaluate a model on healthcare datasets. This command evaluates a specified model across one or more healthcare datasets, with support for dataset-specific arguments and rich output.
## Required Options
[Section titled “Required Options”](#required-options)
| Option | Description |
| -------------- | ------------------------------------------------------------------------------------------- |
| `--model TEXT` | Model name from registry (e.g., ‘Qwen/Qwen3-0.6B’, ‘google/medgemma-4b-it’) **\[required]** |
## Optional Arguments
[Section titled “Optional Arguments”](#optional-arguments)
| Option | Type | Default | Description |
| ---------------------------- | --------------- | ------------ | ----------------------------------------------------------------------------------------------- |
| `--model-path TEXT` | TEXT | - | Model path (local path or HuggingFace model ID). If not provided, uses path from model metadata |
| `--datasets TEXT` | TEXT | all | Comma-separated dataset names (default: evaluate on all datasets) |
| `--dataset-args TEXT` | TEXT | - | Dataset arguments in format ‘dataset:key=val,key2=val2;dataset2:key=val’ |
| `--processor-args TEXT` | TEXT | - | Processor arguments in format ‘dataset.processor:key=val,key2=val2;dataset2.processor:key=val’ |
| `--metric-args TEXT` | TEXT | - | Metric arguments in format ‘metric\_name:key=val,key2=val2;metric2:key=val’ |
| `--batch-size INTEGER` | 1-128 | 8 | Batch size for evaluation |
| `--cache / --no-cache` | FLAG | enabled | Enable or disable caching for evaluation |
| `--output TEXT` | TEXT | results.json | Output file path |
| `--format` | table\|json | table | Results display format |
| `--save-format` | json\|yaml\|csv | json | Results save format |
| `--progress / --no-progress` | FLAG | enabled | Show progress bars during evaluation |
| `--interactive` | FLAG | false | Interactively prompt for missing dataset, processor, and metric arguments |
| `--dry-run` | FLAG | false | Validate arguments and show what would be evaluated without running |
| `--model-config TEXT` | TEXT | - | Path to model configuration file (JSON/YAML) with model-specific parameters |
| `--model-args TEXT` | TEXT | - | Model parameter overrides as JSON string (e.g., ’{“temperature”: 0.7, “top\_p”: 0.9}‘) |
| `--max-samples TEXT` | TEXT | - | Maximum number of samples to use for evaluation (helpful for testing) |
| `--verbose` | FLAG | false | Enable verbose output |
| `--refresh-cache` | FLAG | false | Skip cache lookup and force regeneration of all results |
## Examples
[Section titled “Examples”](#examples)
### Basic Evaluation
[Section titled “Basic Evaluation”](#basic-evaluation)
```bash
karma eval --model "Qwen/Qwen3-0.6B" --datasets "openlifescienceai/pubmedqa"
```
### Multiple Datasets
[Section titled “Multiple Datasets”](#multiple-datasets)
```bash
karma eval --model "Qwen/Qwen3-0.6B" --datasets "openlifescienceai/pubmedqa,openlifescienceai/medmcqa"
```
### With Dataset Arguments
[Section titled “With Dataset Arguments”](#with-dataset-arguments)
```bash
karma eval --model "ai4bharat/indic-conformer-600m-multilingual" \
--datasets "ai4bharat/IN22-Conv" \
--dataset-args "ai4bharat/IN22-Conv:source_language=en,target_language=hi"
```
### With Processor Arguments
[Section titled “With Processor Arguments”](#with-processor-arguments)
```bash
karma eval --model "ai4bharat/indic-conformer-600m-multilingual" \
--datasets "ai4bharat/IN22-Conv" \
--processor-args "ai4bharat/IN22-Conv.devnagari_transliterator:source_script=en,target_script=hi"
```
### With Metric Arguments
[Section titled “With Metric Arguments”](#with-metric-arguments)
```bash
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets "Tonic/Health-Bench-Eval-OSS-2025-07" \
--metric-args "rubric_evaluation:provider_to_use=openai,model_id=gpt-4o-mini,batch_size=5"
```
### With Model Configuration File
[Section titled “With Model Configuration File”](#with-model-configuration-file)
```bash
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/pubmedqa" \
--model-config "config/qwen_medical.json"
```
### With Model Parameter Overrides
[Section titled “With Model Parameter Overrides”](#with-model-parameter-overrides)
```bash
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/pubmedqa" \
--model-args '{"temperature": 0.3, "max_tokens": 1024, "enable_thinking": true}'
```
### Testing with Limited Samples
[Section titled “Testing with Limited Samples”](#testing-with-limited-samples)
```bash
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/pubmedqa" \
--max-samples 10 --verbose
```
### Interactive Mode
[Section titled “Interactive Mode”](#interactive-mode)
```bash
karma eval --model "Qwen/Qwen3-0.6B" --interactive
```
### Dry Run Validation
[Section titled “Dry Run Validation”](#dry-run-validation)
```bash
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/pubmedqa" \
--dry-run --model-args '{"temperature": 0.5}'
```
### Force Cache Refresh
[Section titled “Force Cache Refresh”](#force-cache-refresh)
```bash
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/pubmedqa" \
--refresh-cache
```
## Configuration Priority
[Section titled “Configuration Priority”](#configuration-priority)
Model parameters are applied in the following priority order (highest to lowest):
1. **CLI `--model-args`** - Highest priority
2. **Config file (`--model-config`)** - Overrides metadata defaults
3. **Model metadata defaults** - From registry
4. **CLI `--model-path`** - Sets model path if metadata doesn’t provide one
## Configuration File Formats
[Section titled “Configuration File Formats”](#configuration-file-formats)
### JSON Format
[Section titled “JSON Format”](#json-format)
```json
{
"temperature": 0.7,
"max_tokens": 2048,
"top_p": 0.9,
"enable_thinking": true
}
```
### YAML Format
[Section titled “YAML Format”](#yaml-format)
```yaml
temperature: 0.7
max_tokens: 2048
top_p: 0.9
enable_thinking: true
```
## Common Issues
[Section titled “Common Issues”](#common-issues)
### Model Not Found
[Section titled “Model Not Found”](#model-not-found)
```bash
karma list models
```
### Dataset Not Found
[Section titled “Dataset Not Found”](#dataset-not-found)
```bash
karma list datasets
```
### Invalid JSON in model-args
[Section titled “Invalid JSON in model-args”](#invalid-json-in-model-args)
```bash
# Wrong
--model-args '{temperature: 0.7}'
# Correct
--model-args '{"temperature": 0.7}'
```
## See Also
[Section titled “See Also”](#see-also)
* [Running Evaluations Guide](../user-guide/running-evaluations.md)
* [Model Configuration](../user-guide/models/model-configuration.md)
* [CLI Basics](../user-guide/cli-basics.md)
# karma info
> Complete reference for the karma info commands
The `karma info` command group provides detailed information about models, datasets, and system status.
## Usage
[Section titled “Usage”](#usage)
```bash
karma info [COMMAND] [OPTIONS] [ARGUMENTS]
```
## Subcommands
[Section titled “Subcommands”](#subcommands)
* `karma info model ` - Get detailed information about a specific model
* `karma info dataset ` - Get detailed information about a specific dataset
* `karma info system` - Get system information and status
***
## karma info model
[Section titled “karma info model”](#karma-info-model)
Get detailed information about a specific model including its class details, module location, and implementation info.
### Usage
[Section titled “Usage”](#usage-1)
```bash
karma info model MODEL_NAME [OPTIONS]
```
### Arguments
[Section titled “Arguments”](#arguments)
| Argument | Description |
| ------------ | ---------------------------------------------------------- |
| `MODEL_NAME` | Name of the model to get information about **\[required]** |
### Options
[Section titled “Options”](#options)
| Option | Type | Default | Description |
| ------------- | ---- | ------- | --------------------------------------------- |
| `--show-code` | FLAG | false | Show model class code location and basic info |
### Examples
[Section titled “Examples”](#examples)
```bash
# Basic model information
karma info model "Qwen/Qwen3-0.6B"
# Show code location details
karma info model "google/medgemma-4b-it" --show-code
# Check model that might not exist
karma info model "unknown-model"
```
### Output
[Section titled “Output”](#output)
```bash
$ karma info model "Qwen/Qwen3-0.6B" --show-code
╭────────────────────────────────────────────────────────────────────╮
│ KARMA: Knowledge Assessment and Reasoning for Medical Applications │
╰────────────────────────────────────────────────────────────────────╯
Model Information: Qwen/Qwen3-0.6B
──────────────────────────────────────────────────
Model: Qwen/Qwen3-0.6B
Name Qwen/Qwen3-0.6B
Class QwenThinkingLLM
Module karma.models.qwen
Description:
╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ Qwen language model with specialized thinking capabilities. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Code Location:
File location not available
Constructor Signature:
QwenThinkingLLM(self, model_name_or_path: str, device: str = 'mps', max_tokens: int = 32768, temperature: float = 0.7, top_p: float = 0.9, top_k: Optional = None,
enable_thinking: bool = False, **kwargs)
Usage Examples:
Basic evaluation:
karma eval --model "Qwen/Qwen3-0.6B" --datasets openlifescienceai/pubmedqa
With multiple datasets:
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa,openlifescienceai/mmlu_professional_medicine
With custom arguments:
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa \
--max-samples 100 --batch-size 4
Interactive mode:
karma eval --model "Qwen/Qwen3-0.6B" --interactive
✓ Model information retrieved successfully
```
***
## karma info dataset
[Section titled “karma info dataset”](#karma-info-dataset)
Get detailed information about a specific dataset including its requirements, supported metrics, and usage examples.
### Usage
[Section titled “Usage”](#usage-2)
```bash
karma info dataset DATASET_NAME [OPTIONS]
```
### Arguments
[Section titled “Arguments”](#arguments-1)
| Argument | Description |
| -------------- | ------------------------------------------------------------ |
| `DATASET_NAME` | Name of the dataset to get information about **\[required]** |
### Options
[Section titled “Options”](#options-1)
| Option | Type | Default | Description |
| ----------------- | ---- | ------- | ---------------------------------- |
| `--show-examples` | FLAG | false | Show usage examples with arguments |
| `--show-code` | FLAG | false | Show dataset class code location |
### Examples
[Section titled “Examples”](#examples-1)
```bash
# Basic dataset information
karma info dataset openlifescienceai/pubmedqa
# Show usage examples
karma info dataset "ai4bharat/IN22-Conv" --show-examples
# Show code location
karma info dataset "mdwiratathya/SLAKE-vqa-english" --show-code
# Get info for dataset with required args
karma info dataset "ekacare/MedMCQA-Indic" --show-examples
```
### Output
[Section titled “Output”](#output-1)
```bash
karma info dataset "ai4bharat/IN22-Conv" --show-examples
╭────────────────────────────────────────────────────────────────────╮
│ KARMA: Knowledge Assessment and Reasoning for Medical Applications │
╰────────────────────────────────────────────────────────────────────╯
[13:13:57] INFO Imported model module: karma.models.aws_bedrock model_registry.py:235
INFO Imported model module: karma.models.aws_transcribe_asr model_registry.py:235
[13:13:58] INFO Imported model module: karma.models.base_hf_llm model_registry.py:235
INFO Imported model module: karma.models.docassist_chat model_registry.py:235
INFO Imported model module: karma.models.eleven_labs model_registry.py:235
[13:13:59] INFO Imported model module: karma.models.gemini_asr model_registry.py:235
INFO Imported model module: karma.models.indic_conformer model_registry.py:235
INFO Imported model module: karma.models.medgemma model_registry.py:235
INFO Imported model module: karma.models.openai_asr model_registry.py:235
INFO Imported model module: karma.models.openai_llm model_registry.py:235
INFO Imported model module: karma.models.qwen model_registry.py:235
INFO Imported model module: karma.models.whisper model_registry.py:235
INFO Registry discovery completed: 4/4 successful, 1 cache hits, total time: 1.36s registry_manager.py:70
Dataset Information: ai4bharat/IN22-Conv
──────────────────────────────────────────────────
Dataset: ai4bharat/IN22-Conv
Name ai4bharat/IN22-Conv
Class IN22ConvDataset
Module karma.eval_datasets.in22conv_dataset
Task Type translation
Metrics bleu
Processors devnagari_transliterator
Required Args source_language, target_language
Optional Args domain, processors, confinement_instructions
Default Args source_language=en, domain=conversational
Description:
╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ IN22Conv PyTorch Dataset implementing the new multimodal interface. │
│ Translates from English to specified Indian language. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Usage Examples:
With required arguments:
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets ai4bharat/IN22-Conv \
--dataset-args "ai4bharat/IN22-Conv:source_language=en,target_language=hi"
With optional arguments:
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets ai4bharat/IN22-Conv \
--dataset-args "ai4bharat/IN22-Conv:source_language=en,target_language=hi,domain=conversational,processors=,confinement_instructions="
Interactive mode (prompts for arguments):
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets ai4bharat/IN22-Conv --interactive
✓ Dataset information retrieved successfully
```
## karma info system
[Section titled “karma info system”](#karma-info-system)
Get system information and status including available resources, cache status, and environment details.
### Usage
[Section titled “Usage”](#usage-3)
```bash
karma info system [OPTIONS]
```
### Options
[Section titled “Options”](#options-2)
| Option | Type | Default | Description |
| ------------------- | ---- | ---------- | ------------------------------- |
| `--cache-path TEXT` | TEXT | ./cache.db | Path to cache database to check |
### Examples
[Section titled “Examples”](#examples-2)
```bash
# Basic system information
karma info system
# Check specific cache location
karma info system --cache-path /path/to/cache.db
# Check system status
karma info system --cache-path ~/.karma/cache.db
```
### Output
[Section titled “Output”](#output-2)
```bash
karma info system
╭────────────────────────────────────────────────────────────────────╮
│ KARMA: Knowledge Assessment and Reasoning for Medical Applications │
╰────────────────────────────────────────────────────────────────────╯
Discovering system resources...
[13:14:43] INFO Imported model module: karma.models.aws_bedrock model_registry.py:235
INFO Imported model module: karma.models.aws_transcribe_asr model_registry.py:235
INFO Imported model module: karma.models.base_hf_llm model_registry.py:235
INFO Imported model module: karma.models.docassist_chat model_registry.py:235
INFO Imported model module: karma.models.eleven_labs model_registry.py:235
[13:14:44] INFO Imported model module: karma.models.gemini_asr model_registry.py:235
INFO Imported model module: karma.models.indic_conformer model_registry.py:235
INFO Imported model module: karma.models.medgemma model_registry.py:235
INFO Imported model module: karma.models.openai_asr model_registry.py:235
INFO Imported model module: karma.models.openai_llm model_registry.py:235
INFO Imported model module: karma.models.qwen model_registry.py:235
INFO Imported model module: karma.models.whisper model_registry.py:235
INFO Registry discovery completed: 4/4 successful, 1 cache hits, total time: 1.24s registry_manager.py:70
System Information
──────────────────────────────────────────────────
System Information
Available Models 21
Available Datasets 21
Cache Database ✓ Available (5.0 MB)
Cache Path cache.db
Environment:
Python: 3.10.15
Platform: macOS-15.5-arm64-arm-64bit
Architecture: arm64
Karma CLI: development
Dependencies:
✓ PyTorch: 2.7.1
✓ Transformers: 4.53.0
✓ HuggingFace Datasets: 3.6.0
✓ Rich: unknown
✓ Click: 8.2.1
✓ Weave: 0.51.54
✓ DuckDB: 1.3.1
Usage Examples:
List available resources:
karma list models
karma list datasets
Get detailed information:
karma info model "Qwen/Qwen3-0.6B"
karma info dataset openlifescienceai/pubmedqa
Run evaluation:
karma eval --model "Qwen/Qwen3-0.6B" --datasets openlifescienceai/pubmedqa
Check cache status:
karma info system --cache-path ./cache.db
✓ System information retrieved successfully
```
## Common Usage Patterns
[Section titled “Common Usage Patterns”](#common-usage-patterns)
### Model Discovery and Validation
[Section titled “Model Discovery and Validation”](#model-discovery-and-validation)
```bash
# 1. List available models
karma list models
# 2. Get detailed info about a specific model
karma info model "Qwen/Qwen3-0.6B"
# 3. Check model implementation
karma info model "Qwen/Qwen3-0.6B" --show-code
```
### Dataset Analysis
[Section titled “Dataset Analysis”](#dataset-analysis)
```bash
# 1. Find datasets for a task
karma list datasets --task-type mcqa
# 2. Get detailed dataset info
karma info dataset "openlifescienceai/medmcqa"
# 3. See usage examples with arguments
karma info dataset "ai4bharat/IN22-Conv" --show-examples
```
### System Debugging
[Section titled “System Debugging”](#system-debugging)
```bash
# Check overall system status
karma info system
# Verify dependencies
karma info system --cache-path ~/.karma/cache.db
# Check cache status
karma info system --cache-path ./evaluation_cache.db
```
### Development Workflow
[Section titled “Development Workflow”](#development-workflow)
```bash
# Quick resource check
karma info model "new-model-name"
karma info dataset "new-dataset-name" --show-code
# System health check
karma info system
```
## Error Handling
[Section titled “Error Handling”](#error-handling)
### Model Not Found
[Section titled “Model Not Found”](#model-not-found)
```bash
$ karma info model "nonexistent-model"
Error: Model 'nonexistent-model' not found in registry
Available models: Qwen/Qwen3-0.6B, google/medgemma-4b-it, ...
```
### Dataset Not Found
[Section titled “Dataset Not Found”](#dataset-not-found)
```bash
$ karma info dataset "nonexistent-dataset"
Error: Dataset 'nonexistent-dataset' not found in registry
Available datasets: openlifescienceai/pubmedqa, openlifescienceai/medmcqa, ...
```
### Invalid Cache Path
[Section titled “Invalid Cache Path”](#invalid-cache-path)
```bash
$ karma info system --cache-path /invalid/path/cache.db
Cache Status: Path not accessible
```
# karma interactive
KARMA’s **Interactive Mode** provides a terminal-based experience for benchmarking language and speech models.
This mode walks you through choosing a model, configuring arguments, selecting datasets, reviewing a summary, and executing the evaluations.
***
## 1. Launch Interactive Mode
[Section titled “1. Launch Interactive Mode”](#1-launch-interactive-mode)
Open your terminal in the root folder of your KARMA project and run:
```python
karma interactive
```
This starts the interactive workflow.
You will see a welcome screen indicating that the system is ready.
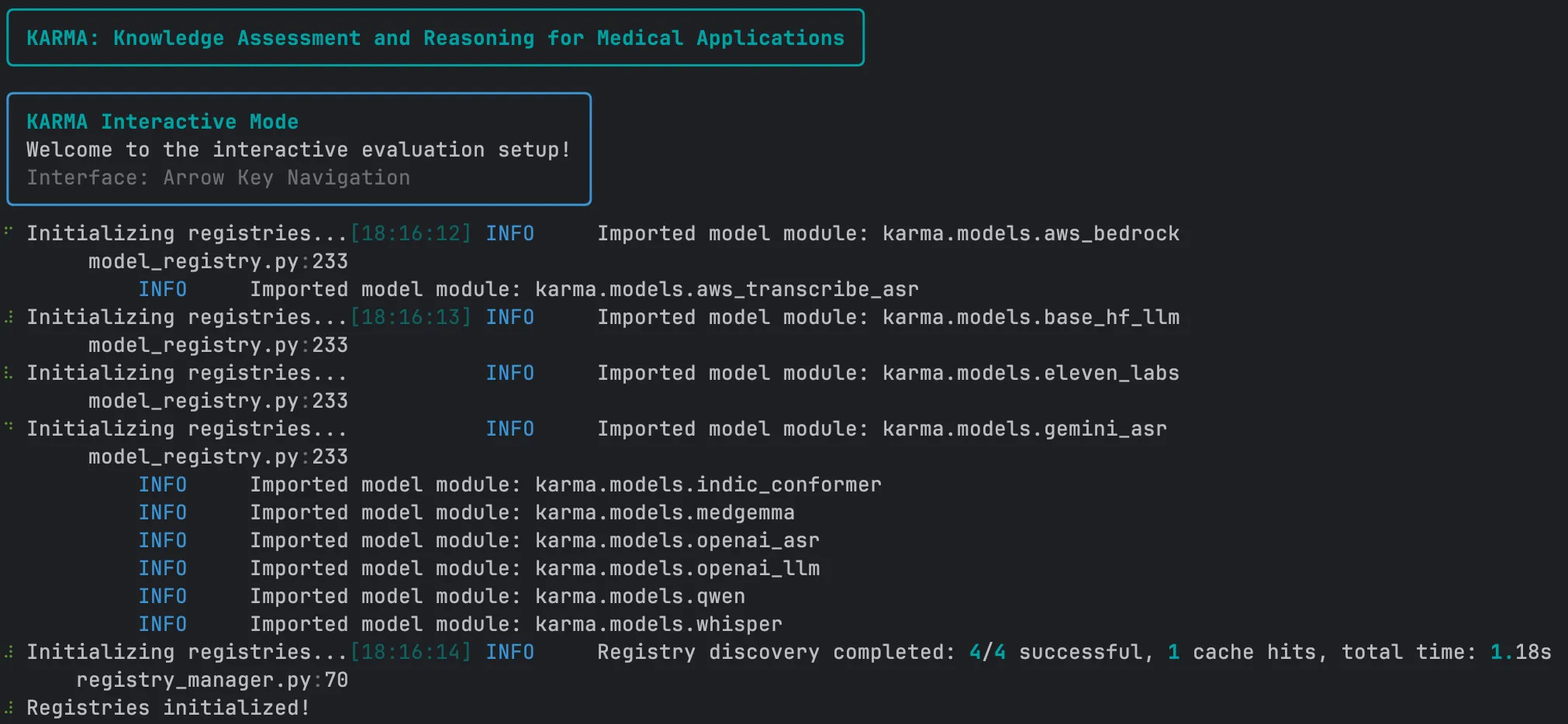
***
## 2. Choose a Model
[Section titled “2. Choose a Model”](#2-choose-a-model)
Next, you’ll get a list of available models.
Use the arrow keys to scroll through and hit Enter to select the one you want.
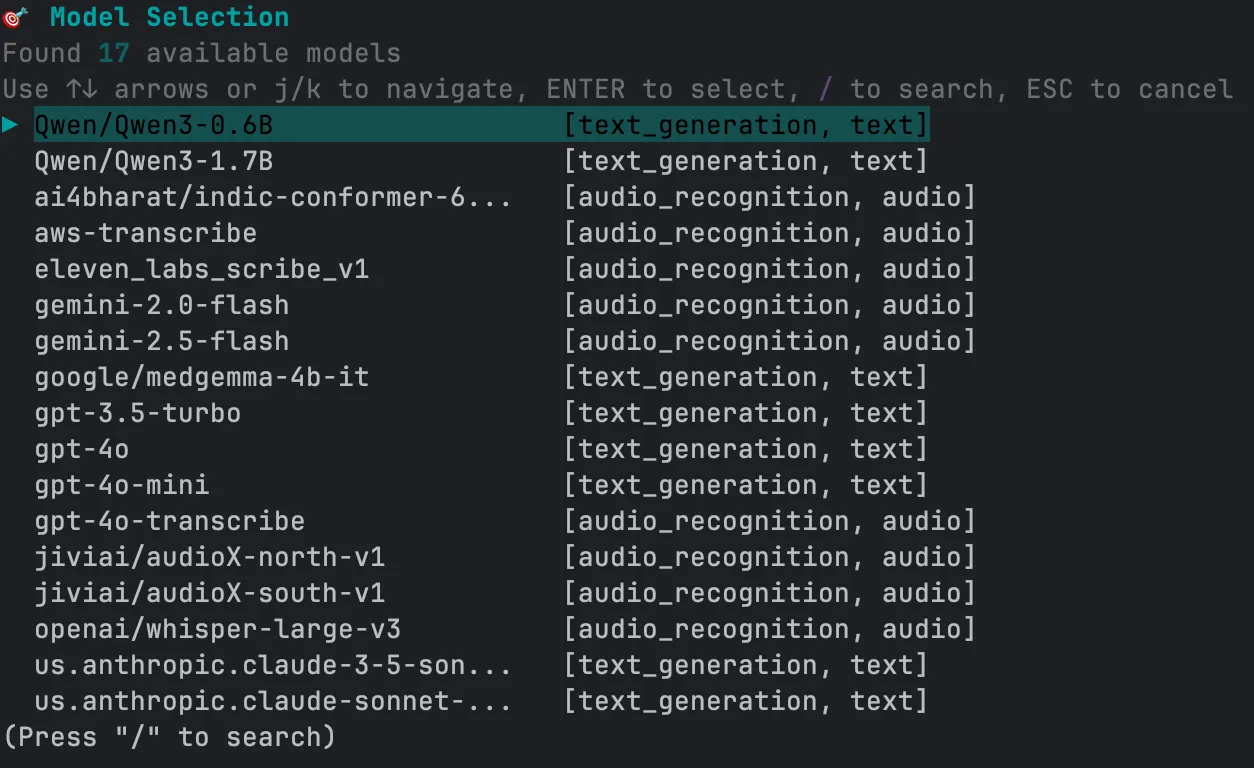
***
## 3. Configure Model Arguments (Optional)
[Section titled “3. Configure Model Arguments (Optional)”](#3-configure-model-arguments-optional)
Some models let you tweak parameters like `temperature` or `max_tokens`. If that’s the case, you’ll be prompted to either:
* Enter your own values
* Or press Enter to skip
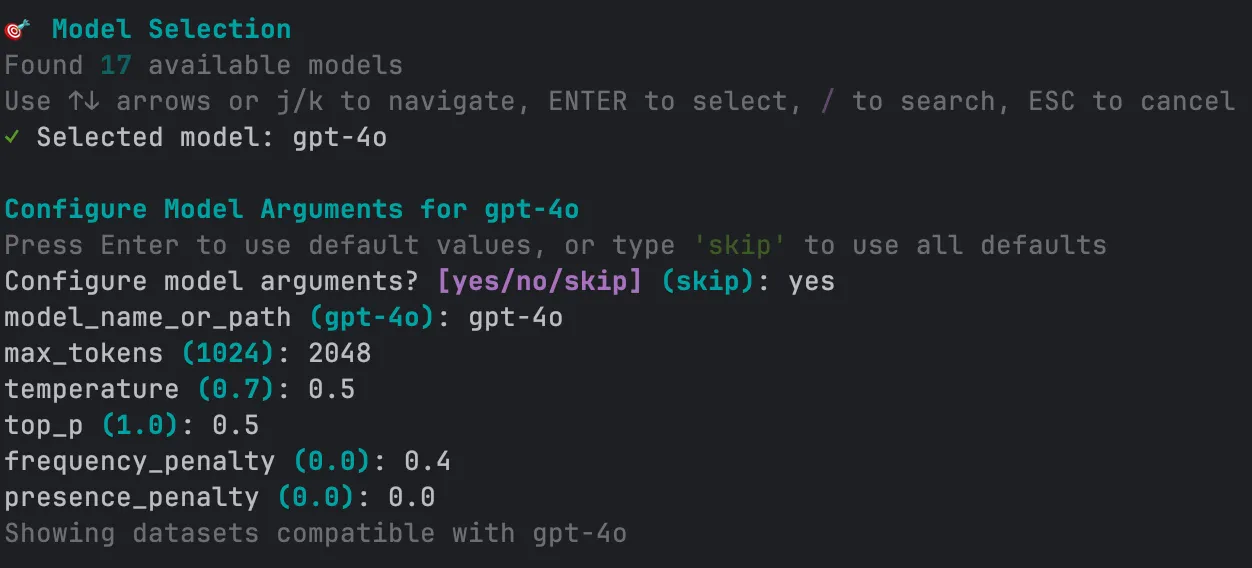
***
## 4. Select a Dataset
[Section titled “4. Select a Dataset”](#4-select-a-dataset)
Choose datasets against which you want to evaluate the model.
* Press `Space` to select one or more datasets
* Hit `Enter` to confirm your selection
* Use the `/` to search for specific datasets
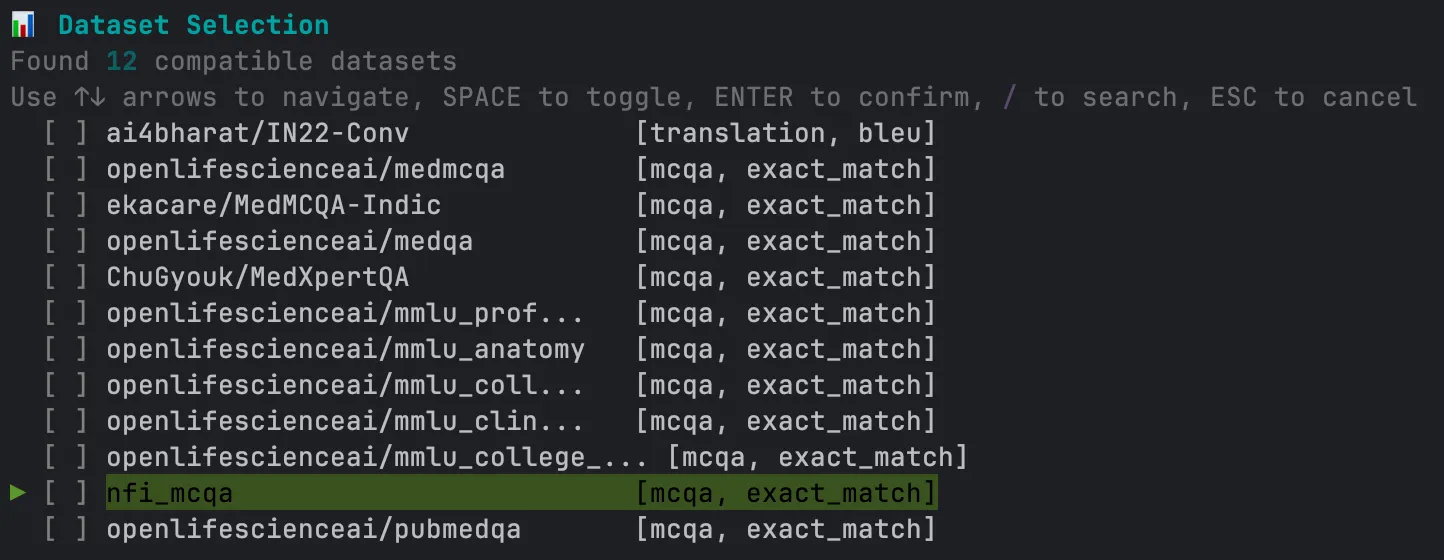
***
## 5. Review Configuration Summary
[Section titled “5. Review Configuration Summary”](#5-review-configuration-summary)
Before continuing, you’ll be shown an **overall summary** of the configuration:
* Selected model and its arguments
* Chosen dataset(s)
Make sure everything looks right before continuing.

***
## 6. Save and Execute Evaluation
[Section titled “6. Save and Execute Evaluation”](#6-save-and-execute-evaluation)
You’ll be asked if you want to:
* Save this configuration for later
* Run the evaluation now or later
Choose whatever works best for your workflow\..

***
## 7. View Results
[Section titled “7. View Results”](#7-view-results)
Once the evaluation begins, you’ll see real-time progress in your terminal.
When it’s finished, the results will be displayed right away for you to review.
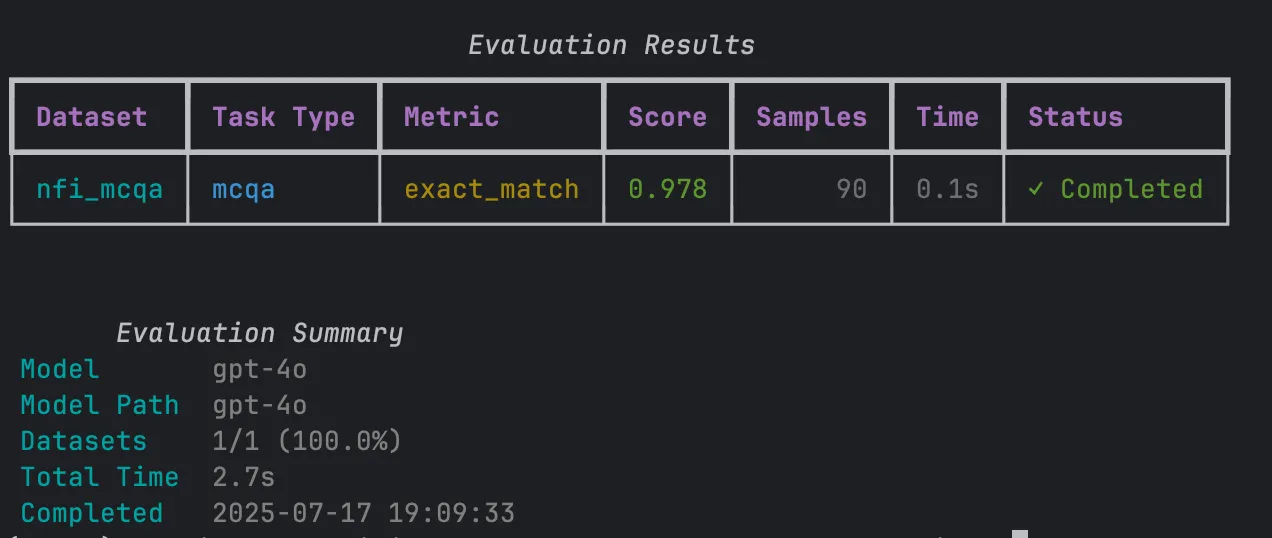
***
# karma list
> Complete reference for the karma list commands
The `karma list` command group provides discovery and listing functionality for all KARMA resources.
## Usage
[Section titled “Usage”](#usage)
```bash
karma list [COMMAND] [OPTIONS]
```
## Subcommands
[Section titled “Subcommands”](#subcommands)
* `karma list models` - List all available models
* `karma list datasets` - List all available datasets
* `karma list metrics` - List all available metrics
* `karma list all` - List all resources (models, datasets, and metrics)
***
## karma list models
[Section titled “karma list models”](#karma-list-models)
List all available models in the registry.
### Usage
[Section titled “Usage”](#usage-1)
```bash
karma list models [OPTIONS]
```
### Options
[Section titled “Options”](#options)
| Option | Type | Default | Description |
| ---------- | ------------------ | ------- | ------------- |
| `--format` | table\|simple\|csv | table | Output format |
### Examples
[Section titled “Examples”](#examples)
```bash
# Table format (default)
karma list models
# Simple text format
karma list models --format simple
# CSV format
karma list models --format csv
```
### Output
[Section titled “Output”](#output)
The table format shows:
* Model Name
* Status (Available/Unavailable)
* Modality (Text, Audio, Vision, etc.)
***
## karma list datasets
[Section titled “karma list datasets”](#karma-list-datasets)
List all available datasets in the registry with optional filtering.
### Usage
[Section titled “Usage”](#usage-2)
```bash
karma list datasets [OPTIONS]
```
### Options
[Section titled “Options”](#options-1)
| Option | Type | Default | Description |
| ------------------ | ------------------ | ------- | -------------------------------------------------------- |
| `--task-type TEXT` | TEXT | - | Filter by task type (e.g., ‘mcqa’, ‘vqa’, ‘translation’) |
| `--metric TEXT` | TEXT | - | Filter by supported metric (e.g., ‘accuracy’, ‘bleu’) |
| `--format` | table\|simple\|csv | table | Output format |
| `--show-args` | FLAG | false | Show detailed argument information |
### Examples
[Section titled “Examples”](#examples-1)
```bash
# List all datasets
karma list datasets
# Filter by task type
karma list datasets --task-type mcqa
# Filter by metric
karma list datasets --metric bleu
# Show detailed argument information
karma list datasets --show-args
# Multiple filters
karma list datasets --task-type translation --metric bleu
# CSV output
karma list datasets --format csv
```
### Output
[Section titled “Output”](#output-1)
The table format shows:
* Dataset Name
* Task Type
* Metrics
* Required Args
* Processors
* Split
* Commit Hash
With `--show-args`, additional details are shown:
* Required arguments with examples
* Optional arguments with defaults
* Processor information
* Usage examples
***
## karma list metrics
[Section titled “karma list metrics”](#karma-list-metrics)
List all available metrics in the registry.
### Usage
[Section titled “Usage”](#usage-3)
```bash
karma list metrics [OPTIONS]
```
### Options
[Section titled “Options”](#options-2)
| Option | Type | Default | Description |
| ---------- | ------------------ | ------- | ------------- |
| `--format` | table\|simple\|csv | table | Output format |
### Examples
[Section titled “Examples”](#examples-2)
```bash
# Table format (default)
karma list metrics
# Simple text format
karma list metrics --format simple
# CSV format
karma list metrics --format csv
```
### Output
[Section titled “Output”](#output-2)
Shows all registered metrics including:
* KARMA native metrics
* HuggingFace Evaluate metrics (as fallback)
***
## karma list all
[Section titled “karma list all”](#karma-list-all)
List both models, datasets, and metrics in one command.
### Usage
[Section titled “Usage”](#usage-4)
```bash
karma list all [OPTIONS]
```
### Options
[Section titled “Options”](#options-3)
| Option | Type | Default | Description |
| ---------- | ------------- | ------- | --------------------------------- |
| `--format` | table\|simple | table | Output format (CSV not supported) |
### Examples
[Section titled “Examples”](#examples-3)
```bash
# Show all resources
karma list all
# Simple format
karma list all --format simple
```
### Output
[Section titled “Output”](#output-3)
Displays:
1. **MODELS** section with all available models
2. **DATASETS** section with all available datasets
3. **METRICS** section with all available metrics
## Common Usage Patterns
[Section titled “Common Usage Patterns”](#common-usage-patterns)
### Discovery Workflow
[Section titled “Discovery Workflow”](#discovery-workflow)
```bash
# 1. See what models are available
karma list models
# 2. See what datasets work with medical tasks
karma list datasets --task-type mcqa
# 3. Check what metrics are available
karma list metrics
# 4. Get detailed info about a specific dataset
karma info dataset openlifescienceai/pubmedqa
```
### Integration Workflow
[Section titled “Integration Workflow”](#integration-workflow)
```bash
# Export for scripts
karma list models --format csv > models.csv
karma list datasets --format csv > datasets.csv
# Check compatibility
karma list datasets --metric exact_match
```
### Development Workflow
[Section titled “Development Workflow”](#development-workflow)
```bash
# Quick overview
karma list all
# Detailed dataset analysis
karma list datasets --show-args --format table
```
## Output Formats
[Section titled “Output Formats”](#output-formats)
### Table Format
[Section titled “Table Format”](#table-format)
* Rich formatted tables with colors and styling
* Best for interactive use
* Default format
### Simple Format
[Section titled “Simple Format”](#simple-format)
* Plain text, one item per line
* Good for scripting and piping
* Minimal formatting
### CSV Format
[Section titled “CSV Format”](#csv-format)
* Comma-separated values
* Best for data processing and exports
* Machine-readable format
## See Also
[Section titled “See Also”](#see-also)
* [Info Commands](./info.md) - Get detailed information about specific resources
* [CLI Basics](../user-guide/cli-basics.md) - General CLI usage
* [Supported Resources](../supported-resources.md) - Complete resource listing
# Supported Resources
> **Note**: This page is auto-generated during the CI/CD pipeline. Last updated: 2025-07-25 10:57:32 UTC
The following resources are currently supported by KARMA:
## Datasets
[Section titled “Datasets”](#datasets)
Currently supported datasets (20 total):
| Dataset | Task Type | Metrics | Required Args | Processors | Split |
| -------------------------------------------------- | ------------------ | ------------------------------- | ---------------------------------- | ----------------------------- | ---------- |
| ChuGyouk/MedXpertQA | mcqa | exact\_match | — | — | test |
| Tonic/Health-Bench-Eval-OSS-2025-07 | rubric\_evaluation | rubric\_evaluation | — | — | oss\_eval |
| ai4bharat/IN22-Conv | translation | bleu | source\_language, target\_language | devnagari\_transliterator | test |
| ai4bharat/IndicVoices | transcription | wer, cer, asr\_semantic\_metric | language | multilingual\_text\_processor | valid |
| ekacare/MedMCQA-Indic | mcqa | exact\_match | subset | — | test |
| ekacare/clinical\_note\_generation\_dataset | text\_to\_json | json\_rubric\_evaluation | — | — | test |
| ekacare/eka-medical-asr-evaluation-dataset | transcription | wer, cer, asr\_semantic\_metric | language | multilingual\_text\_processor | test |
| ekacare/ekacare\_medical\_history\_summarisation | rubric\_evaluation | rubric\_evaluation | — | — | test |
| ekacare/medical\_records\_parsing\_validation\_set | image\_to\_json | json\_rubric\_evaluation | — | — | test |
| ekacare/vistaar\_small\_asr\_eval | transcription | wer, cer, asr\_semantic\_metric | language | multilingual\_text\_processor | test |
| flaviagiammarino/vqa-rad | vqa | exact\_match, tokenised\_f1 | — | — | test |
| mdwiratathya/SLAKE-vqa-english | vqa | exact\_match, tokenised\_f1 | — | — | test |
| openlifescienceai/medmcqa | mcqa | exact\_match | — | — | validation |
| openlifescienceai/medqa | mcqa | exact\_match | — | — | test |
| openlifescienceai/mmlu\_anatomy | mcqa | exact\_match | — | — | test |
| openlifescienceai/mmlu\_clinical\_knowledge | mcqa | exact\_match | — | — | test |
| openlifescienceai/mmlu\_college\_biology | mcqa | exact\_match | — | — | test |
| openlifescienceai/mmlu\_college\_medicine | mcqa | exact\_match | — | — | test |
| openlifescienceai/mmlu\_professional\_medicine | mcqa | exact\_match | — | — | test |
| openlifescienceai/pubmedqa | mcqa | exact\_match | — | — | test |
Recreate this through
```plaintext
karma list datasets
```
## Models
[Section titled “Models”](#models)
Currently supported models (17 total):
| Model Name |
| -------------------------------------------- |
| Qwen/Qwen3-0.6B |
| Qwen/Qwen3-1.7B |
| aws-transcribe |
| docassistchat/default |
| ekacare/parrotlet-v-lite-4b |
| gemini-2.0-flash |
| gemini-2.5-flash |
| google/medgemma-4b-it |
| gpt-3.5-turbo |
| gpt-4.1 |
| gpt-4o |
| gpt-4o-mini |
| gpt-4o-transcribe |
| o3 |
| us.anthropic.claude-3-5-sonnet-20240620-v1:0 |
| us.anthropic.claude-3-5-sonnet-20241022-v2:0 |
| us.anthropic.claude-sonnet-4-20250514-v1:0 |
Recreate this through
```plaintext
karma list models
```
## Metrics
[Section titled “Metrics”](#metrics)
Currently supported metrics (8 total):
| Metric Name |
| ------------------------ |
| bleu |
| cer |
| exact\_match |
| f1 |
| json\_rubric\_evaluation |
| rubric\_evaluation |
| tokenised\_f1 |
| wer |
Recreate this through
```plaintext
karma list metrics
```
## Quick Reference
[Section titled “Quick Reference”](#quick-reference)
Use the following commands to explore available resources:
```bash
# List all models
karma list models
# List all datasets
karma list datasets
# List all metrics
karma list metrics
# List all processors
karma list processors
# Get detailed information about a specific resource
karma info model "Qwen/Qwen3-0.6B"
karma info dataset "openlifescienceai/pubmedqa"
```
## Adding New Resources
[Section titled “Adding New Resources”](#adding-new-resources)
To add new models, datasets, or metrics to KARMA:
* See [Adding Models](/user-guide/add-your-own/add-model.md)
* See [Adding Datasets](/user-guide/add-your-own/add-dataset.md)
* See [Metrics Overview](/user-guide/metrics/metrics_overview.md)
For more detailed information about the registry system, see the [Registry Documentation](/user-guide/registry/registries.md).
# Add dataset
You can create custom datasets by inheriting from `BaseMultimodalDataset` and implementing the `format_item` method to return a properly formatted `DataLoaderIterable`:
```python
from karma.eval_datasets.base_dataset import BaseMultimodalDataset
from karma.registries.dataset_registry import register_dataset
from karma.data_models.dataloader_iterable import DataLoaderIterable
```
Here we will use the `register_dataset` decorator to register and make the dataset discoverable to the CLI. This decorator also has information about the metric to use and any arguments that can be configured.
```python
@register_dataset(
"my_medical_dataset",
metrics=["exact_match", "accuracy"],
task_type="mcqa",
required_args=["split"],
optional_args=["subset"],
default_args={"split": "test"}
)
class MyMedicalDataset(BaseMultimodalDataset):
"""Custom medical dataset."""
def __init__(self, split: str = "test", **kwargs):
self.split = split
super().__init__(**kwargs)
def load_data(self):
# Load your dataset
return your_dataset_loader(split=self.split)
def format_item(self, item):
"""Format each item into DataLoaderIterable format."""
# Example for text-based dataset
return DataLoaderIterable(
input=f"Question: {item['question']}\nChoices: {item['choices']}",
expected_output=item['answer'],
other_args={"question_id": item['id']}
)
```
In the class, we implement the `format_item` method to specify how the output will be like through the `DataLoaderIterable` See (`DataLoaderIterable`)\[user-guide/datasets/data-loader-iterable] for more information.
## Multi-Modal Dataset Example
[Section titled “Multi-Modal Dataset Example”](#multi-modal-dataset-example)
For datasets that combine multiple modalities:
```plaintext
def format_item(self, item):
"""Format multi-modal item."""
return DataLoaderIterable(
input=f"Question: {item['question']}",
images=[item['image_bytes']], # List of image bytes
audio=item.get('audio_bytes'), # Optional audio
expected_output=item['answer'],
other_args={
"question_type": item['type'],
"difficulty": item['difficulty']
}
)
```
## Conversation Dataset Example
[Section titled “Conversation Dataset Example”](#conversation-dataset-example)
For datasets with multi-turn conversations:
```python
from karma.data_models.dataloader_iterable import Conversation, ConversationTurn
def format_item(self, item):
"""Format conversation item."""
conversation_turns = []
for turn in item['conversation']:
conversation_turns.append(
ConversationTurn(
content=turn['content'],
role=turn['role'] # 'user' or 'assistant'
)
)
return DataLoaderIterable(
conversation=Conversation(conversation_turns=conversation_turns),
system_prompt=item.get('system_prompt', ''),
expected_output=item['expected_response']
)
```
The `DataLoaderIterable` format ensures that all datasets work seamlessly with any model type, whether it’s text-only, multi-modal, or conversation-based. Models receive the appropriate data fields and can process them according to their capabilities.
## Using Local Datasets with KARMA
[Section titled “Using Local Datasets with KARMA”](#using-local-datasets-with-karma)
This guide will walk you through how to plug that dataset into KARMA’s evaluation pipeline. Let’s say we are trying to integrate an MCQA dataset.
1. Organize Your Dataset Ensure your dataset is structured correctly.\
Each row should ideally include:
* A question
* A list of options (optional)
* The correct answer
* Optionally: metadata like category, generic name, or citation
2. Set Up a Custom Dataset Class KARMA supports registering your own datasets using a decorator.
```python
@register_dataset(
dataset_name="mcqa-local",
split="test",
metrics=["exact_match"],
task_type="mcqa",
)
class LocalDataset(BaseMultimodalDataset):
...
```
This decorator registers your dataset with KARMA for evaluations.
3. Load your Dataset In your Dataset class, load your dataset file.\
You can use any format supported by pandas, such as CSV or Parquet.
```python
def __init__(self, ...):
self.data_path =
if not os.path.exists(self.data_path):
raise FileNotFoundError(f"Dataset file not found: {self.data_path}")
self.df = pd.read_parquet(self.data_path)
...
```
4. Implement the format\_item Method Each row in your dataset will be converted into an input-output pair for the model.
```python
def format_item(self, sample: Dict[str, Any]) -> DataLoaderIterable:
input_text = self._format_question(sample["data"])
correct_answer = sample["data"]["ground_truth"]
prompt = self.confinement_instructions.replace("", input_text)
dataloader_item = DataLoaderIterable(
input=prompt, expected_output=correct_answer
)
dataloader_item.conversation = None
return dataloader_item
```
5. Iterate Over the Dataset Implement `__iter__()` to yield formatted examples.
```python
def __iter__(self) -> Generator[Dict[str, Any], None, None]:
if self.dataset is None:
self.dataset = list(self.load_eval_dataset())
for idx, sample in enumerate(self.dataset):
if self.max_samples is not None and idx >= self.max_samples:
break
item = self.format_item(sample)
yield item
```
6. Handle Model Output Extract the model’s predictions.
```python
def extract_prediction(self, response: str) -> Tuple[str, bool]:
answer, success = "", False
if "Final Answer:" in response:
answer = response.split("Final Answer:")[1].strip()
if answer.startswith("(") and answer.endswith(")"):
answer = answer[1:-1]
success = True
return answer, success
```
7. Yield Examples for Evaluation Read from your DataFrame and return structured examples.
```python
def load_eval_dataset(self, ...):
for _, row in self.df.iterrows():
prediction = None
parsed_output = row.get("model_output_parsed", None)
if isinstance(parsed_output, dict):
prediction = parsed_output.get("prediction", None)
yield {
"id": row["index"],
"data": {
"question": row["question"],
"options": row["options"],
"ground_truth": row["ground_truth"],
},
"prediction": prediction,
"metadata": {
"generic_name": row.get("generic_name", None),
"category": row.get("category", None),
"citation": row.get("citation", None),
},
}
```
# Add metric
You can create custom evaluation metrics by inheriting from `BaseMetric`:
```python
from karma.metrics.base_metric_abs import BaseMetric
from karma.registries.metrics_registry import register_metric
@register_metric("medical_accuracy")
class MedicalAccuracyMetric(BaseMetric):
"""Medical-specific accuracy metric with domain weighting."""
def __init__(self, medical_term_weight=1.5):
self.medical_term_weight = medical_term_weight
self.medical_terms = self._load_medical_terms()
def evaluate(self, predictions, references, **kwargs):
"""Evaluate with medical term weighting."""
total_score = 0
total_weight = 0
for pred, ref in zip(predictions, references):
# Standard comparison
is_correct = pred.lower().strip() == ref.lower().strip()
# Apply weighting for medical terms
weight = self._get_weight(ref)
total_weight += weight
if is_correct:
total_score += weight
accuracy = total_score / total_weight if total_weight > 0 else 0.0
return {
"medical_accuracy": accuracy,
"total_examples": len(predictions),
"total_weight": total_weight
}
def _get_weight(self, text):
"""Get weight based on medical content."""
weight = 1.0
for term in self.medical_terms:
if term in text.lower():
weight = self.medical_term_weight
break
return weight
def _load_medical_terms(self):
"""Load medical terminology."""
return ["diabetes", "hypertension", "surgery", "medication",
"diagnosis", "treatment", "symptom", "therapy"]
```
### Using Custom Metrics
[Section titled “Using Custom Metrics”](#using-custom-metrics)
Once registered, custom metrics are automatically discovered and need to be specified on the dataset that you want to use.
Let’s say you would like to change the openlifescienceai/pubmedqa Update the @register\_dataset in `eval_datasets/pubmedqa.py`
```python
@register_dataset(
DATASET_NAME,
commit_hash=COMMIT_HASH,
split=SPLIT,
metrics=["exact_match", "medical_accuracy"], # we added the medical accuracy metric to this dataset
task_type="mcqa",
)
class PubMedMCQADataset(MedQADataset):
...
```
```bash
# The metric will be automatically used if specified in dataset registration
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets my_medical_dataset
```
# Add model
This guide provides a walkthrough for adding new models to the KARMA evaluation framework. KARMA supports diverse model types including local HuggingFace models, API-based services, and multi-modal models across text, audio, image, and video domains.
## Architecture Overview
[Section titled “Architecture Overview”](#architecture-overview)
### Base Model System
[Section titled “Base Model System”](#base-model-system)
All models in KARMA inherit from the `BaseModel` abstract class, which provides a unified interface for model loading, inference, and data processing. This ensures consistency across all model implementations and makes it easy to swap between different models during evaluation.
#### Required Method Implementation
[Section titled “Required Method Implementation”](#required-method-implementation)
Every custom model must implement these four core methods:
```python
from karma.models.base_model_abs import BaseModel
from karma.data_models.dataloader_iterable import DataLoaderIterable
```
**1. Basic Class Structure**
```python
class MyModel(BaseModel):
def load_model(self):
"""Initialize model and tokenizer/processor
This method is called once when the model is first used.
Load your model weights, tokenizer, and any required components here.
Set self.is_loaded = True when complete.
"""
pass
```
**2. Main Inference Method**
```python
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
"""Main inference method that processes a batch of inputs
This is the primary method called during evaluation.
It should handle the complete inference pipeline:
1. Check if model is loaded (call load_model if needed)
2. Preprocess inputs
3. Run model inference
4. Postprocess outputs
5. Return list of string predictions
"""
pass
```
**3. Input Preprocessing**
```python
def preprocess(self, inputs: List[DataLoaderIterable]) -> Any:
"""Convert raw inputs to model-ready format
Transform the DataLoaderIterable objects into the format
your model expects (e.g., tokenized tensors, processed images).
Handle batching, padding, and any required data transformations.
"""
pass
```
**4. Output Postprocessing**
```python
def postprocess(self, outputs: Any) -> List[str]:
"""Process model outputs to final format
Convert raw model outputs (logits, tokens, etc.) into
clean string responses that can be evaluated.
Apply any filtering, decoding, or formatting needed.
"""
pass
```
### ModelMeta System
[Section titled “ModelMeta System”](#modelmeta-system)
The `ModelMeta` class provides comprehensive metadata management for model registration. This system allows KARMA to understand your model’s capabilities, requirements, and how to instantiate it properly.
#### Understanding ModelMeta Components
[Section titled “Understanding ModelMeta Components”](#understanding-modelmeta-components)
**Import Required Classes**
```python
from karma.data_models.model_meta import ModelMeta, ModelType, ModalityType
```
**Basic ModelMeta Structure**
```python
model_meta = ModelMeta(
# Model identification - use format "organization/model-name"
name="my-model/my-model-name",
# Human-readable description for documentation
description="Description of my model",
# Python import path to your model class
loader_class="karma.models.my_model.MyModel",
)
```
**Configuration Parameters**
```python
# Parameters passed to your model's __init__ method
loader_kwargs={
"temperature": 0.7, # Generation temperature
"max_tokens": 2048, # Maximum output length
# Add any custom parameters your model needs
},
```
**Model Classification**
```python
# What type of task this model performs
model_type=ModelType.TEXT_GENERATION, # or AUDIO_RECOGNITION, MULTIMODAL, etc.
# What input types the model can handle
modalities=[ModalityType.TEXT], # TEXT, IMAGE, AUDIO, VIDEO
# What frameworks/libraries the model uses
framework=["PyTorch", "Transformers"],
```
### Data Flow
[Section titled “Data Flow”](#data-flow)
Models process data through the `DataLoaderIterable` structure. This standardized format ensures that all models receive data in a consistent way, regardless of the underlying dataset format.
#### Understanding DataLoaderIterable
[Section titled “Understanding DataLoaderIterable”](#understanding-dataloaderiterable)
The system automatically converts dataset entries into this structure before passing them to your model:
```python
from karma.data_models.dataloader_iterable import DataLoaderIterable
```
**Core Data Fields**
```python
data = DataLoaderIterable(
# Primary text input (questions, prompts, etc.)
input="Your text input here",
# System-level instructions for the model
system_prompt="System instructions",
# Ground truth answer (used for evaluation, not model input)
expected_output="Ground truth for evaluation",
)
```
**Multi-Modal Data Fields**
```python
# Image data as PIL Images or raw bytes
images=None, # List of PIL.Image or bytes objects
# Audio data in various formats
audio=None, # Audio file path, bytes, or numpy array
# Video data (for video-capable models)
video=None, # Video file path or processed frames
```
**Conversation Support**
```python
# Multi-turn conversation history
conversation=None, # List of {"role": "user/assistant", "content": "..."}}
```
**Custom Extensions**
```python
# Additional dataset-specific information
other_args={"custom_key": "custom_value"} # Any extra metadata
```
#### How Your Model Receives Data
[Section titled “How Your Model Receives Data”](#how-your-model-receives-data)
Your model’s `run()` method receives a list of these objects:
```python
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
for item in inputs:
text_input = item.input # Main question/prompt
system_msg = item.system_prompt # System instructions
images = item.images # Any associated images
# Process each item...
```
## Model Implementation Steps
[Section titled “Model Implementation Steps”](#model-implementation-steps)
### Step 1: Create Model Class
[Section titled “Step 1: Create Model Class”](#step-1-create-model-class)
Create a new Python file in the `karma/models/` directory:
karma/models/my\_model.py
```python
import torch
from typing import List, Dict, Any
from karma.models.base_model_abs import BaseModel
from karma.data_models.dataloader_iterable import DataLoaderIterable
class MyModel(BaseModel):
def __init__(self, model_name_or_path: str, **kwargs):
super().__init__(model_name_or_path, **kwargs)
self.temperature = kwargs.get("temperature", 0.7)
self.max_tokens = kwargs.get("max_tokens", 2048)
def load_model(self):
"""Load the model and tokenizer"""
# Example for HuggingFace model
from transformers import AutoModelForCausalLM, AutoTokenizer
self.model = AutoModelForCausalLM.from_pretrained(
self.model_name_or_path,
device_map=self.device,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
self.tokenizer = AutoTokenizer.from_pretrained(
self.model_name_or_path,
trust_remote_code=True
)
self.is_loaded = True
def preprocess(self, inputs: List[DataLoaderIterable]) -> Dict[str, torch.Tensor]:
"""Convert inputs to model format"""
batch_inputs = []
for item in inputs:
# Handle different input types
if item.conversation:
# Multi-turn conversation
messages = item.conversation.messages
text = self.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
else:
# Single input
text = item.input
batch_inputs.append(text)
# Tokenize batch
encoding = self.tokenizer(
batch_inputs,
padding=True,
truncation=True,
return_tensors="pt",
max_length=self.max_tokens
)
return encoding.to(self.device)
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
"""Generate model outputs"""
if not self.is_loaded:
self.load_model()
# Preprocess inputs
model_inputs = self.preprocess(inputs)
# Generate outputs
with torch.no_grad():
outputs = self.model.generate(
**model_inputs,
max_new_tokens=self.max_tokens,
temperature=self.temperature,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
# Decode outputs
generated_texts = []
for i, output in enumerate(outputs):
# Remove input tokens from output
input_length = model_inputs["input_ids"][i].shape[0]
generated_tokens = output[input_length:]
text = self.tokenizer.decode(
generated_tokens,
skip_special_tokens=True
)
generated_texts.append(text)
return self.postprocess(generated_texts)
def postprocess(self, outputs: List[str]) -> List[str]:
"""Clean up generated outputs"""
cleaned_outputs = []
for output in outputs:
# Remove any unwanted tokens or formatting
cleaned = output.strip()
cleaned_outputs.append(cleaned)
return cleaned_outputs
```
### Step 2: Create ModelMeta Configuration
[Section titled “Step 2: Create ModelMeta Configuration”](#step-2-create-modelmeta-configuration)
Add ModelMeta definitions at the end of your model file:
```python
# karma/models/my_model.py (continued)
from karma.registries.model_registry import register_model_meta
from karma.data_models.model_meta import ModelMeta, ModelType, ModalityType
# Define model variants
MyModelSmall = ModelMeta(
name="my-org/my-model-small",
description="Small version of my model",
loader_class="karma.models.my_model.MyModel",
loader_kwargs={
"temperature": 0.7,
"max_tokens": 2048,
},
model_type=ModelType.TEXT_GENERATION,
modalities=[ModalityType.TEXT],
framework=["PyTorch", "Transformers"],
n_parameters=7_000_000_000,
memory_usage_mb=14_000,
)
MyModelLarge = ModelMeta(
name="my-org/my-model-large",
description="Large version of my model",
loader_class="karma.models.my_model.MyModel",
loader_kwargs={
"temperature": 0.7,
"max_tokens": 4096,
},
model_type=ModelType.TEXT_GENERATION,
modalities=[ModalityType.TEXT],
framework=["PyTorch", "Transformers"],
n_parameters=70_000_000_000,
memory_usage_mb=140_000,
)
# Register models
register_model_meta(MyModelSmall)
register_model_meta(MyModelLarge)
```
### Step 3: Verify Registration
[Section titled “Step 3: Verify Registration”](#step-3-verify-registration)
Test that your model is properly registered:
```bash
# List all models to verify registration
karma list models
# Check specific model details
karma list models --name "my-org/my-model-small"
```
## Model Types and Examples
[Section titled “Model Types and Examples”](#model-types-and-examples)
### Text Generation Models
[Section titled “Text Generation Models”](#text-generation-models)
**HuggingFace Transformers Model:**
```python
class HuggingFaceTextModel(BaseModel):
def load_model(self):
from transformers import AutoModelForCausalLM, AutoTokenizer
self.model = AutoModelForCausalLM.from_pretrained(
self.model_name_or_path,
device_map=self.device,
torch_dtype=torch.bfloat16
)
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name_or_path)
self.is_loaded = True
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
# Implementation similar to Step 1 example
pass
```
**API-Based Model:**
```python
class APITextModel(BaseModel):
def __init__(self, model_name_or_path: str, **kwargs):
super().__init__(model_name_or_path, **kwargs)
self.api_key = kwargs.get("api_key")
self.base_url = kwargs.get("base_url")
def load_model(self):
import openai
self.client = openai.OpenAI(
api_key=self.api_key,
base_url=self.base_url
)
self.is_loaded = True
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
if not self.is_loaded:
self.load_model()
responses = []
for item in inputs:
response = self.client.chat.completions.create(
model=self.model_name_or_path,
messages=[{"role": "user", "content": item.input}],
temperature=self.temperature,
max_tokens=self.max_tokens
)
responses.append(response.choices[0].message.content)
return responses
```
### Audio Recognition Models
[Section titled “Audio Recognition Models”](#audio-recognition-models)
```python
class AudioRecognitionModel(BaseModel):
def load_model(self):
import whisper
self.model = whisper.load_model(self.model_name_or_path)
self.is_loaded = True
def preprocess(self, inputs: List[DataLoaderIterable]) -> List[Any]:
audio_data = []
for item in inputs:
if item.audio:
audio_data.append(item.audio)
else:
raise ValueError("Audio data is required for audio recognition")
return audio_data
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
if not self.is_loaded:
self.load_model()
audio_data = self.preprocess(inputs)
transcriptions = []
for audio in audio_data:
result = self.model.transcribe(audio)
transcriptions.append(result["text"])
return transcriptions
```
### Multi-Modal Models
[Section titled “Multi-Modal Models”](#multi-modal-models)
```python
class MultiModalModel(BaseModel):
def load_model(self):
from transformers import AutoProcessor, AutoModelForVision2Seq
self.processor = AutoProcessor.from_pretrained(self.model_name_or_path)
self.model = AutoModelForVision2Seq.from_pretrained(
self.model_name_or_path,
device_map=self.device,
torch_dtype=torch.bfloat16
)
self.is_loaded = True
def preprocess(self, inputs: List[DataLoaderIterable]) -> Dict[str, torch.Tensor]:
batch_inputs = []
for item in inputs:
# Handle text + image inputs
if item.images and item.input:
batch_inputs.append({
"text": item.input,
"images": item.images
})
else:
raise ValueError("Both text and images are required")
# Process with multi-modal processor
processed = self.processor(
text=[item["text"] for item in batch_inputs],
images=[item["images"] for item in batch_inputs],
return_tensors="pt",
padding=True
)
return processed.to(self.device)
def run(self, inputs: List[DataLoaderIterable]) -> List[str]:
if not self.is_loaded:
self.load_model()
model_inputs = self.preprocess(inputs)
with torch.no_grad():
outputs = self.model.generate(
**model_inputs,
max_new_tokens=self.max_tokens,
temperature=self.temperature
)
# Decode outputs
generated_texts = self.processor.batch_decode(
outputs, skip_special_tokens=True
)
return generated_texts
```
### ModelMeta Examples for Different Types
[Section titled “ModelMeta Examples for Different Types”](#modelmeta-examples-for-different-types)
```python
# Text generation model
TextModelMeta = ModelMeta(
name="my-org/text-model",
loader_class="karma.models.my_model.HuggingFaceTextModel",
model_type=ModelType.TEXT_GENERATION,
modalities=[ModalityType.TEXT],
framework=["PyTorch", "Transformers"],
)
# Audio recognition model
AudioModelMeta = ModelMeta(
name="my-org/audio-model",
loader_class="karma.models.my_model.AudioRecognitionModel",
model_type=ModelType.AUDIO_RECOGNITION,
modalities=[ModalityType.AUDIO],
framework=["PyTorch", "Whisper"],
audio_sample_rate=16000,
supported_audio_formats=["wav", "mp3", "flac"],
)
# Multi-modal model
MultiModalMeta = ModelMeta(
name="my-org/multimodal-model",
loader_class="karma.models.my_model.MultiModalModel",
model_type=ModelType.MULTIMODAL,
modalities=[ModalityType.TEXT, ModalityType.IMAGE],
framework=["PyTorch", "Transformers"],
vision_encoder_dim=1024,
)
```
### Logging
[Section titled “Logging”](#logging)
```python
import logging
logger = logging.getLogger(__name__)
def load_model(self):
logger.info(f"Loading model: {self.model_name_or_path}")
# ... model loading code ...
logger.info("Model loaded successfully")
```
Your model is now ready to be integrated into the KARMA evaluation framework! The system will automatically discover and make it available through the CLI and evaluation pipelines.
# Add processor
Processors are used for tweak the output of the model and then running evaluation on that output. This is typically required in cases when normalizing text for different languages or dialects. We have implmemented these for ASR specific datasets but you can use it for any dataset.
### Step 1: Create Processor Class
[Section titled “Step 1: Create Processor Class”](#step-1-create-processor-class)
karma/processors/my\_custom\_processor.py
```python
from karma.processors.base import BaseProcessor
from karma.registries.processor_registry import register_processor
@register_processor("medical_text_normalizer")
class MedicalTextNormalizer(BaseProcessor):
"""Processor for normalizing medical text."""
def __init__(self, normalize_units=True, expand_abbreviations=True):
self.normalize_units = normalize_units
self.expand_abbreviations = expand_abbreviations
self.medical_abbreviations = {
"bp": "blood pressure",
"hr": "heart rate",
"temp": "temperature",
"mg": "milligrams",
"ml": "milliliters"
}
def process(self, text: str, **kwargs) -> str:
"""Process medical text with normalization."""
if self.expand_abbreviations:
text = self._expand_abbreviations(text)
if self.normalize_units:
text = self._normalize_units(text)
return text
def _expand_abbreviations(self, text: str) -> str:
"""Expand medical abbreviations."""
for abbrev, expansion in self.medical_abbreviations.items():
text = text.replace(abbrev, expansion)
return text
def _normalize_units(self, text: str) -> str:
"""Normalize medical units."""
# Add unit normalization logic
return text
```
### Step 2: Register and Use
[Section titled “Step 2: Register and Use”](#step-2-register-and-use)
```python
# Via CLI
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets my_medical_dataset \
--processor-args "my_medical_dataset.medical_text_normalizer:normalize_units=True"
# Programmatically
from karma.registries.processor_registry import get_processor
processor = get_processor("medical_text_normalizer", normalize_units=True)
```
## Integration Patterns
[Section titled “Integration Patterns”](#integration-patterns)
### Dataset Integration
[Section titled “Dataset Integration”](#dataset-integration)
Processors can be integrated directly with dataset registration:
```python
@register_dataset(
"my_medical_dataset",
processors=["general_text_processor", "medical_text_normalizer"],
processor_configs={
"general_text_processor": {"lowercase": True},
"medical_text_normalizer": {"normalize_units": True}
}
)
class MyMedicalDataset(BaseMultimodalDataset):
# Dataset implementation
pass
```
## Advanced Use Cases
[Section titled “Advanced Use Cases”](#advanced-use-cases)
### Chain Multiple Processors
[Section titled “Chain Multiple Processors”](#chain-multiple-processors)
```python
# Create processor chain
from karma.registries.processor_registry import get_processor
processors = [
get_processor("general_text_processor", lowercase=True),
get_processor("medical_text_normalizer", normalize_units=True),
get_processor("multilingual_text_processor", target_language="en")
]
# Apply chain to dataset
def process_chain(text: str) -> str:
for processor in processors:
text = processor.process(text)
return text
```
### Language-Specific Processing
[Section titled “Language-Specific Processing”](#language-specific-processing)
```python
# Language-specific processor selection
def get_language_processor(language: str):
if language in ["hi", "bn", "ta"]:
return get_processor("devnagari_transliterator")
else:
return get_processor("general_text_processor")
```
## Best Practices
[Section titled “Best Practices”](#best-practices)
1. **Chain Order**: Consider the order of processors in the chain
2. **Language Handling**: Use appropriate processors for different languages
3. **Performance**: Be mindful of processing overhead for large datasets
4. **Testing**: Validate processor output with sample data
5. **Configuration**: Make processors configurable for different use cases
# How CLI Arguments Flow to Model Classes
> Understanding how initialization arguments pass from the CLI through the registry system to model constructors
This guide explains the internal mechanics of how CLI arguments flow through KARMA’s architecture to initialize model classes. Understanding this flow is essential for debugging model configuration issues and extending the framework.
## Overview
[Section titled “Overview”](#overview)
Arguments flow through four main layers with a clear hierarchy:
```plaintext
CLI Command (eval.py)
↓
Argument Processing (_prepare_model_overrides)
↓
Model Registry (model_registry.py)
↓
Model Class (__init__)
```
## Parameter Precedence Hierarchy
[Section titled “Parameter Precedence Hierarchy”](#parameter-precedence-hierarchy)
KARMA uses a layered configuration system where each layer can override the previous one:
1. **Model Metadata Defaults** (lowest priority)
2. **CLI Model Path** (if provided)
3. **Config File Parameters** (if provided)
4. **CLI Arguments** (highest priority)
## Detailed Flow
[Section titled “Detailed Flow”](#detailed-flow)
### 1. CLI Layer (`karma/cli/commands/eval.py`)
[Section titled “1. CLI Layer (karma/cli/commands/eval.py)”](#1-cli-layer-karmaclicommandsevalpy)
The evaluation command accepts multiple ways to configure models:
```bash
# Basic usage with model metadata defaults
karma eval --model "gpt-4o"
# Override with CLI arguments
karma eval --model "gpt-4o" --model-kwargs '{"temperature": 0.7, "max_tokens": 1024}'
# Use config file
karma eval --model "gpt-4o" --model-config config.json
# Override model path
karma eval --model "gpt-4o" --model-path "path/to/custom/model"
```
**Key CLI Options:**
* `--model`: Model name from registry (required)
* `--model-path`: Override model path
* `--model-config`: JSON/YAML config file path
* `--model-args`: JSON string of parameter overrides
**Code Reference:** `karma/cli/commands/eval.py:36-106`
### 2. Argument Processing (`_prepare_model_overrides`)
[Section titled “2. Argument Processing (\_prepare\_model\_overrides)”](#2-argument-processing-_prepare_model_overrides)
The `_prepare_model_overrides()` function merges configuration from all sources:
```python
def _prepare_model_overrides(
model_name: str,
model_path: str,
model_config: str,
model_kwargs: str,
console: Console,
) -> dict:
```
**Processing Steps:**
1. **Load Model Metadata Defaults**
```python
model_meta = model_registry.get_model_meta(model_name)
final_config.update(model_meta.loader_kwargs)
```
2. **Apply CLI Model Path**
```python
if model_path:
final_config["model_name_or_path"] = model_path
```
3. **Load Config File**
```python
if model_config:
config_data = _load_config_file(model_config)
final_config.update(config_data)
```
4. **Apply CLI Overrides**
```python
if model_kwargs:
cli_overrides = json.loads(model_kwargs)
final_config.update(cli_overrides)
```
**Code Reference:** `karma/cli/commands/eval.py:702-775`
### 3. Model Registry (`karma/registries/model_registry.py`)
[Section titled “3. Model Registry (karma/registries/model\_registry.py)”](#3-model-registry-karmaregistriesmodel_registrypy)
The registry handles model instantiation through `_get_model_from_meta()`:
```python
def _get_model_from_meta(self, name: str, **override_kwargs) -> BaseModel:
model_meta = self.model_metas[name]
model_class = model_meta.get_loader_class()
# Merge kwargs: defaults < model_meta < overrides
final_kwargs = model_meta.merge_kwargs(override_kwargs)
# Ensure model path is set
final_kwargs["model_name_or_path"] = (
model_meta.name if model_meta.model_path is None else model_meta.model_path
)
return model_class(**final_kwargs)
```
**Key Functions:**
* Retrieves model metadata and loader class
* Merges default kwargs with overrides
* Ensures `model_name_or_path` is properly set
* Instantiates the model class with final parameters
**Code Reference:** `karma/registries/model_registry.py:117-139`
### 4. Model Class Instantiation
[Section titled “4. Model Class Instantiation”](#4-model-class-instantiation)
The model class receives the merged parameters in its `__init__` method:
```python
class OpenAILLM(BaseModel):
def __init__(
self,
model_name_or_path: str = "gpt-4o",
api_key: Optional[str] = None,
max_tokens: int = 4096,
temperature: float = 0.0,
top_p: float = 1.0,
frequency_penalty: float = 0.0,
presence_penalty: float = 0.0,
max_workers: int = 4,
**kwargs,
):
super().__init__(model_name_or_path=model_name_or_path, **kwargs)
# Set instance variables from parameters
self.model_id = model_name_or_path
self.api_key = api_key or os.getenv("OPENAI_API_KEY")
self.max_tokens = max_tokens
self.temperature = temperature
# ... other parameters
```
**Code Reference:** `karma/models/openai_llm.py:21-67`
## ModelMeta Configuration
[Section titled “ModelMeta Configuration”](#modelmeta-configuration)
Models define their default parameters using ModelMeta objects:
```python
GPT4o_LLM = ModelMeta(
name="gpt-4o",
description="OpenAI GPT-4o language model",
loader_class="karma.models.openai_llm.OpenAILLM",
loader_kwargs={
"model_name_or_path": "gpt-4o",
"max_tokens": 4096,
"temperature": 0.0,
"top_p": 1.0,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
},
model_type=ModelType.TEXT_GENERATION,
modalities=[ModalityType.TEXT],
# ... other metadata
)
```
These defaults serve as the base configuration layer that can be overridden through the CLI.
**Code Reference:** `karma/models/openai_llm.py:228-247`
## Practical Examples
[Section titled “Practical Examples”](#practical-examples)
### Example 1: Using Defaults
[Section titled “Example 1: Using Defaults”](#example-1-using-defaults)
```bash
karma eval --model "gpt-4o" --datasets "pubmedqa"
```
**Flow:**
1. CLI passes `model="gpt-4o"`
2. Registry loads GPT4o\_LLM metadata
3. Uses default `loader_kwargs`: `temperature=0.0`, `max_tokens=4096`
4. Instantiates `OpenAILLM(model_name_or_path="gpt-4o", temperature=0.0, ...)`
### Example 2: CLI Override
[Section titled “Example 2: CLI Override”](#example-2-cli-override)
```bash
karma eval --model "gpt-4o" --model-kwargs '{"temperature": 0.7, "max_tokens": 1024}'
```
**Flow:**
1. CLI passes overrides: `temperature=0.7`, `max_tokens=1024`
2. `_prepare_model_overrides()` merges: defaults + CLI overrides
3. Final config: `temperature=0.7`, `max_tokens=1024`, other defaults unchanged
4. Instantiates `OpenAILLM(temperature=0.7, max_tokens=1024, ...)`
### Example 3: Config File + CLI Override
[Section titled “Example 3: Config File + CLI Override”](#example-3-config-file--cli-override)
**config.json:**
```json
{
"temperature": 0.5,
"max_tokens": 2048,
"top_p": 0.9
}
```
**CLI:**
```bash
karma eval --model "gpt-4o" --model-config config.json --model-kwargs '{"temperature": 0.7}'
```
**Flow:**
1. Loads defaults from metadata
2. Applies config file: `temperature=0.5`, `max_tokens=2048`, `top_p=0.9`
3. Applies CLI override: `temperature=0.7` (overrides config file)
4. Final: `temperature=0.7`, `max_tokens=2048`, `top_p=0.9`
## Orchestrator Integration
[Section titled “Orchestrator Integration”](#orchestrator-integration)
The MultiDatasetOrchestrator receives the final configuration:
```python
orchestrator = MultiDatasetOrchestrator(
model_name=model,
model_path=final_model_path,
model_kwargs=model_overrides, # The merged configuration
console=console,
)
```
**Code Reference:** `karma/cli/commands/eval.py:299-304`
## Debugging Tips
[Section titled “Debugging Tips”](#debugging-tips)
### 1. Check Parameter Precedence
[Section titled “1. Check Parameter Precedence”](#1-check-parameter-precedence)
If your model isn’t using expected parameters, verify the precedence:
* CLI args override everything
* Config file overrides metadata defaults
* Metadata provides base defaults
### 2. Validate JSON Format
[Section titled “2. Validate JSON Format”](#2-validate-json-format)
CLI model arguments must be valid JSON:
```bash
# ✅ Correct
--model-kwargs '{"temperature": 0.7, "max_tokens": 1024}'
# ❌ Incorrect (single quotes inside)
--model-kwargs '{"temperature": 0.7, "max_tokens": '1024'}'
```
### 3. Model Path Resolution
[Section titled “3. Model Path Resolution”](#3-model-path-resolution)
The `model_name_or_path` parameter is set in this order:
1. CLI `--model-path` (if provided)
2. Config file `model_name_or_path` (if in config)
3. ModelMeta `name` field (fallback)
### 4. Environment Variables
[Section titled “4. Environment Variables”](#4-environment-variables)
Some models (like OpenAI) use environment variables:
```python
self.api_key = api_key or os.getenv("OPENAI_API_KEY")
```
Make sure required environment variables are set when using models that depend on them.
## Summary
[Section titled “Summary”](#summary)
The argument flow system provides flexible model configuration while maintaining clear precedence rules. Understanding this flow helps with:
* Debugging configuration issues
* Creating custom model implementations
* Building configuration management tools
* Extending the framework with new parameter sources
The key insight is that configuration flows through multiple layers, with each layer able to override the previous one, giving users maximum flexibility while providing sensible defaults.
# CLI Basics
KARMA provides a comprehensive CLI built with Click and Rich for an excellent user experience.
## Basic Commands
[Section titled “Basic Commands”](#basic-commands)
```bash
# Get help
karma --help
# Check version
karma --version
# List all available models
karma list models
# List all available datasets
karma list datasets
# Get detailed information about a model
karma info model qwen
# Get detailed information about a dataset
karma info dataset openlifescienceai/pubmedqa
```
## CLI Structure
[Section titled “CLI Structure”](#cli-structure)
The KARMA CLI is organized into several main commands:
* **`karma eval`** - Run model evaluations
* **`karma list`** - List available resources (models, datasets, metrics)
* **`karma info`** - Get detailed information about specific resources
* **`karma interactive`** - Interactive mode of the CLI
* **`karma --help`** - Get help for any command
## Getting Help
[Section titled “Getting Help”](#getting-help)
You can get help for any command by adding `--help`:
```bash
# General help
karma --help
# Help for evaluation command
karma eval --help
# Help for list command
karma list --help
# Help for info command
karma info --help
```
## Evaluate With Additional Args
[Section titled “Evaluate With Additional Args”](#evaluate-with-additional-args)
This guide explains how to pass additional arguments to control datasets, models, processors, and metrics during evaluation using the `karma eval` command.
KARMA CLI supports fine-grained control using the following flags:
* `--dataset-args`
* `--model-args`
* `--processor-args`
* `--metrics-args`
These arguments let you filter subsets, customize generation parameters, modify input processing, and tune evaluation metrics.
#### General Syntax
[Section titled “General Syntax”](#general-syntax)
```bash
# Test with Additional Args
karma eval \
--model \
--datasets \
--dataset-args ":param1=value1,param2=value2" \
--model-args "param=value" \
--processor-args ":param=value" \
--metrics-args ":param=value"
```
### Example
[Section titled “Example”](#example)
#### Dataset Args
[Section titled “Dataset Args”](#dataset-args)
```bash
--dataset-args "ekacare/MedMCQA-Indic:subset=as"
```
#### Model Args
[Section titled “Model Args”](#model-args)
```bash
--model-args "temperature=0.7,max_tokens=256"
```
#### Processor Args
[Section titled “Processor Args”](#processor-args)
```bash
--processor-args "ai4bharat/IN22-Conv.devnagari_transliterator:source_script=en,target_script=hi"
```
#### Metrics Args
[Section titled “Metrics Args”](#metrics-args)
```bash
--metrics-args "accuracy:threshold=0.8"
```
## Next Steps
[Section titled “Next Steps”](#next-steps)
* **Run your first evaluation**: See [Running Evaluations](running-evaluations)
* **Learn about models**: Check out the [Models Guide](../models/overview)
* **Explore datasets**: Read the [Datasets Guide](datasets/datasets_overview)
# DataLoaderIterable
All datasets in KARMA format their data using the `DataLoaderIterable` class, which provides a unified interface for different modalities and data types. The `format_item` method in each dataset transforms raw data into this standardized format.
### DataLoaderIterable Structure
[Section titled “DataLoaderIterable Structure”](#dataloaderiterable-structure)
```python
from karma.data_models.dataloader_iterable import DataLoaderIterable
# The complete structure
data_item = DataLoaderIterable(
input=None, # Text input for the model
images=None, # Image data (PIL Image or bytes)
audio=None, # Audio data (bytes)
conversation=None, # Multi-turn conversation structure
system_prompt=None, # System instructions for the model
expected_output=None, # Ground truth answer
rubric_to_evaluate=None, # Rubric criteria for evaluation
other_args=None # Additional metadata
)
```
### Text Dataset Example: PubMedMCQA
[Section titled “Text Dataset Example: PubMedMCQA”](#text-dataset-example-pubmedmcqa)
Text-based datasets use the `input` and `expected_output` fields:
karma/eval\_datasets/pubmedmcqa\_dataset.py
```python
def format_item(self, sample: Dict[str, Any], **kwargs):
input_text = self._format_question(sample["data"])
# Parse correct answer from Correct Option field
correct_option = sample["data"]["Correct Option"]
context = "\n".join(sample["data"]["Context"])
prompt = self.confinement_instructions.replace("", context).replace(
"", input_text
)
processed_sample = DataLoaderIterable(
input=prompt, # Formatted question with context
expected_output=correct_option, # Correct answer (e.g., "A")
)
return processed_sample
```
**Key Features:**
* `input`: Contains the formatted question with context and instructions
* `expected_output`: Contains the correct answer for evaluation
* No other modalities are used for pure text tasks
### Audio Dataset Example: IndicVoices
[Section titled “Audio Dataset Example: IndicVoices”](#audio-dataset-example-indicvoices)
Audio datasets use the `audio` field for input data:
karma/eval\_datasets/indicvoices.py
```python
def format_item(self, sample: Dict[str, Any]) -> DataLoaderIterable:
audio_info = sample.get("audio_filepath", {})
audio_data = audio_info.get("bytes")
return DataLoaderIterable(
audio=audio_data, # Audio bytes for ASR
expected_output=sample.get("text", ""), # Ground truth transcription
other_args={"language": sample.get("lang", "unknown")}, # Language metadata
)
```
**Key Features:**
* `audio`: Contains the raw audio data as bytes
* `expected_output`: Contains the ground truth transcription
* `other_args`: Stores additional metadata like language information
* No `input` field needed as audio is the primary input
### Image Dataset Example: SLAKE VQA
[Section titled “Image Dataset Example: SLAKE VQA”](#image-dataset-example-slake-vqa)
Vision-language datasets combine text and images:
karma/eval\_datasets/slake\_dataset.py
```python
def format_item(self, sample: Dict[str, Any]) -> DataLoaderIterable:
question = sample.get("question", "")
answer = sample.get("answer", "").lower()
image = sample["image"]["bytes"]
# Create VQA prompt
prompt = self.confinement_instructions.replace("", question)
processed_sample = DataLoaderIterable(
input=prompt, # Text question with instructions
expected_output=answer, # Ground truth answer
images=[image], # Image data as bytes (in a list)
)
return processed_sample
```
**Key Features:**
* `input`: Contains the formatted question text
* `images`: Contains image data as bytes (wrapped in a list for batch processing)
* `expected_output`: Contains the ground truth answer
* Multi-modal models can process both text and image inputs
### Rubric Dataset Example: Health-Bench
[Section titled “Rubric Dataset Example: Health-Bench”](#rubric-dataset-example-health-bench)
Rubric-based datasets use conversations and structured evaluation criteria:
karma/eval\_datasets/rubrics/rubric\_base\_dataset.py
```python
def format_item(self, sample: Dict[str, Any]) -> DataLoaderIterable:
# Extract conversation turns
conversation = []
for conversation_turn in sample["prompt"]:
conversation.append(
ConversationTurn(
content=conversation_turn["content"],
role=conversation_turn["role"],
)
)
conversation = Conversation(conversation_turns=conversation)
# Extract rubric criteria
criterions = []
for rubric_item in sample["rubrics"]:
criterions.append(
RubricCriteria(
criterion=rubric_item["criterion"],
points=rubric_item["points"],
tags=rubric_item.get("tags", []),
)
)
processed_sample = DataLoaderIterable(
conversation=conversation, # Multi-turn conversation
rubric_to_evaluate=criterions, # Structured evaluation criteria
system_prompt=self.system_prompt, # System instructions
)
return processed_sample
```
**Key Features:**
* `conversation`: Contains structured multi-turn conversations
* `rubric_to_evaluate`: Contains structured evaluation criteria
* `system_prompt`: Contains system-level instructions
* No `expected_output` as evaluation is done via rubric scoring
# Datasets Guide
This guide covers working with datasets in KARMA, from using built-in datasets to creating your own custom implementations.
## Built-in Datasets
[Section titled “Built-in Datasets”](#built-in-datasets)
KARMA supports 14+ medical datasets across multiple modalities:
```bash
# List available datasets
karma list datasets
# Get dataset information
karma info dataset openlifescienceai/pubmedqa
# Use a dataset
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa
```
### Text-based Datasets
[Section titled “Text-based Datasets”](#text-based-datasets)
* **openlifescienceai/pubmedqa** - PubMed Question Answering
* **openlifescienceai/medmcqa** - Medical Multiple Choice QA
* **openlifescienceai/medqa** - Medical Question Answering
* **ChuGyouk/MedXpertQA** - Medical Expert QA
### Vision-Language Datasets
[Section titled “Vision-Language Datasets”](#vision-language-datasets)
* **mdwiratathya/SLAKE-vqa-english** - Structured Language And Knowledge Extraction
* **flaviagiammarino/vqa-rad** - Visual Question Answering for Radiology
### Audio Datasets
[Section titled “Audio Datasets”](#audio-datasets)
* **ai4bharat/indicvoices\_r** - Text to speech dataset that could be used for ASR evaluation as well.
* **ai4bharat/indicvoices** - ASR dataset - Indic Voices Recognition
### Translation Datasets
[Section titled “Translation Datasets”](#translation-datasets)
* **ai4bharat/IN22-Conv** - Indic Language Conversation Translation
### Rubric-Based Evaluation Datasets
[Section titled “Rubric-Based Evaluation Datasets”](#rubric-based-evaluation-datasets)
* **ekacare/ekacare\_medical\_history\_summarisation** - Medical History Summarization with rubric evaluation
* **Tonic/Health-Bench-Eval-OSS-2025-07** - Health-Bench evaluation with rubric scoring
These datasets include structured rubric criteria that define evaluation points, scoring weights, and categorization tags. The rubric evaluation is performed by an LLM evaluator (OpenAI or AWS Bedrock) that assesses model responses against multiple criteria simultaneously.
## Viewing Available Datasets
[Section titled “Viewing Available Datasets”](#viewing-available-datasets)
```bash
# List all available datasets
karma list datasets
# Get detailed information about a specific dataset
karma info dataset openlifescienceai/pubmedqa
```
## Using Datasets
[Section titled “Using Datasets”](#using-datasets)
```bash
# Use specific dataset
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa
# Use multiple datasets
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/pubmedqa,openlifescienceai/medmcqa"
```
## Dataset Configuration
[Section titled “Dataset Configuration”](#dataset-configuration)
### Dataset-Specific Arguments
[Section titled “Dataset-Specific Arguments”](#dataset-specific-arguments)
Some datasets require additional configuration:
```bash
# Translation datasets with language pairs
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets "ai4bharat/IN22-Conv" \
--dataset-args "ai4bharat/IN22-Conv:source_language=en,target_language=hi"
# Datasets with specific splits
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets "openlifescienceai/medmcqa" \
--dataset-args "openlifescienceai/medmcqa:split=validation"
# Rubric-based datasets with custom system prompts
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets "Tonic/Health-Bench-Eval-OSS-2025-07" \
--metrics "rubric_evaluation" \
--dataset-args "Tonic/Health-Bench-Eval-OSS-2025-07:system_prompt=You are a medical expert assistant" \
--metric-args "rubric_evaluation:provider_to_use=openai,model_id=gpt-4o-mini,batch_size=5"
```
# Installation Guide
This guide provides detailed installation instructions for KARMA on different platforms and environments.
## Installation Methods
[Section titled “Installation Methods”](#installation-methods)
KARMA can be installed through pip and also uv
Installing UV
Run this command
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
Or see UV docs here -
* pip
```bash
pip install karma-medeval
```
* uv
```bash
uv pip install karma-medeval
```
Or add to your uv project through
```bash
uv add karma-medeval
```
# Verify installation
[Section titled “Verify installation”](#verify-installation)
```bash
karma --version
```
## Optional Dependencies
[Section titled “Optional Dependencies”](#optional-dependencies)
### Audio Support
[Section titled “Audio Support”](#audio-support)
For audio-related datasets and ASR metrics:
* pip
```bash
pip install "karma-medeval[audio]"
```
* uv
```bash
uv pip install "karma-medeval[audio]"
```
This includes:
* `jiwer` - Word Error Rate calculations
* `num2words` - Number to word conversion
* `torchaudio` - Audio processing
### Install with all dependencies
[Section titled “Install with all dependencies”](#install-with-all-dependencies)
* pip
Install the development dependencies through pip
```bash
pip install "karma-medeval[all]"
```
* uv
```bash
uv pip install "karma-medeval[all]"
```
## Development installation
[Section titled “Development installation”](#development-installation)
### Clone the repository
[Section titled “Clone the repository”](#clone-the-repository)
```bash
# Clone the repository
git clone https://github.com/eka-care/KARMA-OpenMedEvalKit.git
cd KARMA-OpenMedEvalKit
```
### Install developer version
[Section titled “Install developer version”](#install-developer-version)
Then run either of these commands for developer installation
* pip
Install the development dependencies through pip
```bash
pip install -e .
```
* uv
```bash
uv sync
```
### Install with all dependencies
[Section titled “Install with all dependencies”](#install-with-all-dependencies-1)
* pip
Install the development dependencies through pip
```bash
pip install -e ".[all]"
```
* uv
```bash
uv sync --all-extras
```
## Environment Configuration
[Section titled “Environment Configuration”](#environment-configuration)
Create a `.env` file in your project root:
```bash
# Required: HuggingFace token for model downloads
HUGGINGFACE_TOKEN=your_token_here
# Cache configuration
KARMA_CACHE_TYPE=duckdb
KARMA_CACHE_PATH=./cache.db
# Logging
LOG_LEVEL=INFO
# Optional: OpenAI API key (for certain metrics)
OPENAI_API_KEY=your_openai_key
# Optional: DynamoDB configuration (for production)
# KARMA_CACHE_TYPE=dynamodb
# AWS_REGION=us-east-1
# DYNAMODB_TABLE_NAME=karma-cache
```
#### HuggingFace Token
[Section titled “HuggingFace Token”](#huggingface-token)
To access gated models or datasets, set this environment variable with your Huggingface token.
You can see the guide to create tokens [here](https://huggingface.co/docs/hub/en/security-tokens)
```bash
# Login to HuggingFace
huggingface-cli login
# Or set environment variable
export HUGGINGFACE_TOKEN=your_token_here
```
# Metrics Guide
This guide covers understanding evaluation metrics in KARMA, interpreting results, and creating custom metrics.
## Available Metrics
[Section titled “Available Metrics”](#available-metrics)
```bash
# List all available metrics
karma list metrics
# Check which metrics a dataset uses
karma info dataset openlifescienceai/pubmedqa
```
### Text-Based Metrics
[Section titled “Text-Based Metrics”](#text-based-metrics)
* **exact\_match**: Percentage of predictions that exactly match the ground truth
* **accuracy**: Overall accuracy (same as exact\_match for most datasets)
* **bleu**: BLEU score for text generation tasks
### Speech Recognition Metrics
[Section titled “Speech Recognition Metrics”](#speech-recognition-metrics)
* **wer**: Word Error Rate (WER) for speech recognition tasks
* **cer**: Character Error (CER) Rate for speech recognition tasks
* **asr\_semantic\_metrics**:
* *semantic\_wer/semantic\_cer*: Semantic WER/CER after applying language-specific orthographic normalizations
* *entity\_wer*: Entity WER using the enttity taggings from the dataset
## Metric Interpretation
[Section titled “Metric Interpretation”](#metric-interpretation)
### Exact Match
[Section titled “Exact Match”](#exact-match)
* **Range**: 0.0 to 1.0 (higher is better)
* **Meaning**: Percentage of predictions that exactly match the reference
* **Use case**: Multiple choice questions, classification tasks
### BLEU Score
[Section titled “BLEU Score”](#bleu-score)
* **Range**: 0.0 to 1.0 (higher is better)
* **Meaning**: Measures overlap between generated and reference text
* **Use case**: Text generation, translation tasks
### Word Error Rate (WER)
[Section titled “Word Error Rate (WER)”](#word-error-rate-wer)
* **Range**: 0.0+ (lower is better)
* **Meaning**: Percentage of words that need to be changed to match reference
* **Use case**: Speech recognition, transcription tasks
### Character Error Rate (CER)
[Section titled “Character Error Rate (CER)”](#character-error-rate-cer)
* **Range**: 0.0+ (lower is better)
* **Meaning**: Percentage of characters that need to be changed
* **Use case**: Speech recognition, fine-grained text evaluation
### Rubric-Based Evaluation Example
[Section titled “Rubric-Based Evaluation Example”](#rubric-based-evaluation-example)
Based on healthbench’s rubric evaluation criteria, rubrics can be evaluated through rubric\_evaluation.
```bash
# Use rubric evaluation metric with OpenAI
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets "Tonic/Health-Bench-Eval-OSS-2025-07" \
--metric-args "rubric_evaluation:provider_to_use=openai,model_id=gpt-4o-mini,batch_size=5"
# Use with AWS Bedrock
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets "ekacare/ekacare_medical_history_summarisation" \
--metric-args "rubric_evaluation:provider_to_use=bedrock,model_id=anthropic.claude-3-haiku-20240307-v1:0,batch_size=10"
```
The rubric evaluation metric automatically uses the rubric criteria defined in the dataset. For example, Health-Bench datasets contain rubrics like:
```json
{
"criterion": "States that oral iron supplements can lead to unpleasant gastrointestinal side effects",
"points": 5,
"tags": ["level:cluster", "cluster:accuracy", "axis:medical_knowledge"]
}
```
The metric evaluates model responses against these criteria using an LLM evaluator and returns:
* Overall score (0-1 based on achieved points vs total possible points)
* Individual rubric evaluations with explanations
* Tag-based performance breakdowns
* Statistical measures (std dev, bootstrap standard error)
# Built-in Models
KARMA includes several pre-configured models optimized for medical AI evaluation across different modalities.
## Available Models Overview
[Section titled “Available Models Overview”](#available-models-overview)
```bash
# List all available models
karma list models
# Expected output:
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓
┃ Model Name ┃ Status ┃ Modality ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩
│ Qwen/Qwen3-0.6B │ ✓ Available │ Text │
│ Qwen/Qwen3-1.7B │ ✓ Available │ Text │
│ google/medgemma-4b-it │ ✓ Available │ Text + Vision │
│ gpt-4o │ ✓ Available │ Text │
│ gpt-4o-mini │ ✓ Available │ Text │
│ gpt-3.5-turbo │ ✓ Available │ Text │
│ us.anthropic.claude-3-5-sonnet-20241022-v2:0│ ✓ Available │ Text │
│ us.anthropic.claude-sonnet-4-20250514-v1:0 │ ✓ Available │ Text │
│ ai4bharat/indic-conformer-600m-multilingual │ ✓ Available │ Audio │
│ aws-transcribe │ ✓ Available │ Audio │
│ gpt-4o-transcribe │ ✓ Available │ Audio │
│ gemini-2.0-flash │ ✓ Available │ Audio │
│ gemini-2.5-flash │ ✓ Available │ Audio │
│ eleven_labs │ ✓ Available │ Audio │
└─────────────────────────────────────────────┴─────────────┴────────────────────┘
```
## Text Generation Models
[Section titled “Text Generation Models”](#text-generation-models)
### Qwen Models
[Section titled “Qwen Models”](#qwen-models)
Alibaba’s Qwen models with specialized thinking capabilities for medical reasoning:
```bash
# Get detailed model information
karma info model "Qwen/Qwen3-0.6B"
# Basic usage
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa
# Advanced configuration with thinking mode
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa \
--model-args '{"enable_thinking": true, "temperature": 0.3}'
```
**Available Models:**
* **Qwen/Qwen3-0.6B**: Compact 0.6B parameter model
* **Qwen/Qwen3-1.7B**: Larger 1.7B parameter model
### MedGemma models
[Section titled “MedGemma models”](#medgemma-models)
Google’s medical-specialized Gemma models with vision capabilities:
```bash
# MedGemma for specialized medical tasks
karma eval --model "google/medgemma-4b-it" \
--datasets openlifescienceai/medmcqa \
--model-args '{"temperature": 0.1, "max_tokens": 512}'
# MedGemma with image analysis
karma eval --model "google/medgemma-4b-it" \
--datasets medical_image_dataset \
--model-args '{"temperature": 0.01, "max_tokens": 1024}'
```
### OpenAI models
[Section titled “OpenAI models”](#openai-models)
OpenAI’s GPT models for comprehensive text generation: When invoking OpenAI models, multiprocessing is leveraged to make multiple calls concurrently.
```bash
# GPT-4o for complex medical reasoning
karma eval --model "gpt-4o" \
--datasets openlifescienceai/pubmedqa \
--model-args '{"temperature": 0.7, "max_tokens": 1024}'
# GPT-4o Mini for efficient processing
karma eval --model "gpt-4o-mini" \
--datasets medical_qa_dataset \
--model-args '{"temperature": 0.3, "max_tokens": 512}'
# GPT-3.5 Turbo for cost-effective inference
karma eval --model "gpt-3.5-turbo" \
--datasets simple_medical_tasks \
--model-args '{"temperature": 0.5, "max_tokens": 1024}'
```
**Available Models:**
* **gpt-4o**: Latest GPT-4 Omni model with advanced reasoning
* **gpt-4o-mini**: Compact version of GPT-4o for efficient processing
* **gpt-3.5-turbo**: Cost-effective model for simpler tasks
### Anthropic models via AWS Bedrock
[Section titled “Anthropic models via AWS Bedrock”](#anthropic-models-via-aws-bedrock)
Anthropic’s Claude models via AWS Bedrock: When invoking Bedrock models, multiprocessing is leveraged to make multiple calls concurrently.
```bash
# Claude 3.5 Sonnet for advanced medical reasoning
karma eval --model "us.anthropic.claude-3-5-sonnet-20241022-v2:0" \
--datasets complex_medical_cases \
--model-args '{"temperature": 0.7, "max_tokens": 1024}'
# Claude Sonnet 4 for cutting-edge performance
karma eval --model "us.anthropic.claude-sonnet-4-20250514-v1:0" \
--datasets advanced_medical_reasoning \
--model-args '{"temperature": 0.3, "max_tokens": 2048}'
```
**Available Models:**
* **us.anthropic.claude-3-5-sonnet-20241022-v2:0**: Claude 3.5 Sonnet v2
* **us.anthropic.claude-sonnet-4-20250514-v1:0**: Latest Claude Sonnet 4
## Audio Recognition Models
[Section titled “Audio Recognition Models”](#audio-recognition-models)
### IndicConformer ASR
[Section titled “IndicConformer ASR”](#indicconformer-asr)
AI4Bharat’s Conformer model for Indian languages:
```bash
# Indian language speech recognition
karma eval \
--model "ai4bharat/indic-conformer-600m-multilingual" \
--datasets "ai4bharat/indicvoices_r" \
--batch-size 1 \
--dataset-args "ai4bharat/indicvoices_r:language=Hindi" \
--processor-args "ai4bharat/indicvoices_r.general_text_processor:language=Hindi"
```
**Key Features:**
* **22 Indian Languages**: Complete coverage of constitutional languages
* **Medical Audio**: Optimized for healthcare speech recognition
* **Conformer Architecture**: State-of-the-art speech recognition architecture
* **Regional Dialects**: Handles diverse Indian language variations
* **Open Source**: MIT licensed with open weights
### Cloud ASR Services
[Section titled “Cloud ASR Services”](#cloud-asr-services)
Enterprise-grade speech recognition for production deployments:
#### AWS Transcribe
[Section titled “AWS Transcribe”](#aws-transcribe)
```bash
# AWS Transcribe with automatic language detection
karma eval --model aws-transcribe \
--datasets medical_audio_dataset \
--model-args '{"region_name": "us-east-1", "s3_bucket": "your-bucket"}'
```
#### Google Gemini ASR
[Section titled “Google Gemini ASR”](#google-gemini-asr)
```bash
# Gemini 2.0 Flash for audio transcription
karma eval --model gemini-2.0-flash \
--datasets medical_audio_dataset \
--model-args '{"thinking_budget": 1000}'
# Gemini 2.5 Flash for enhanced performance
karma eval --model gemini-2.5-flash \
--datasets medical_audio_dataset \
--model-args '{"thinking_budget": 2000}'
```
**Available Models:**
* **gemini-2.0-flash**: Fast transcription with thinking capabilities
* **gemini-2.5-flash**: Enhanced model with improved accuracy
#### OpenAI Whisper ASR
[Section titled “OpenAI Whisper ASR”](#openai-whisper-asr)
```bash
# OpenAI Whisper for high-accuracy transcription
karma eval --model gpt-4o-transcribe \
--datasets medical_audio_dataset \
--model-args '{"language": "en"}'
```
#### ElevenLabs ASR
[Section titled “ElevenLabs ASR”](#elevenlabs-asr)
```bash
# ElevenLabs for specialized audio processing
karma eval --model eleven_labs \
--datasets medical_audio_dataset \
--model-args '{"diarize": false, "tag_audio_events": false}'
```
## Getting Model Information
[Section titled “Getting Model Information”](#getting-model-information)
```bash
# Get detailed information about any model
$ karma info model "Qwen/Qwen3-0.6B"
Model Information: Qwen/Qwen3-0.6B
──────────────────────────────────────────────────
Model: Qwen/Qwen3-0.6B
Name Qwen/Qwen3-0.6B
Class QwenThinkingLLM
Module karma.models.qwen
Description:
╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ Qwen language model with specialized thinking capabilities. │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Constructor Signature:
QwenThinkingLLM(self, model_name_or_path: str, device: str = 'mps', max_tokens: int = 32768, temperature: float = 0.7, top_p: float = 0.9, top_k:
Optional = None, enable_thinking: bool = False, **kwargs)
Usage Examples:
Basic evaluation:
karma eval --model "Qwen/Qwen3-0.6B" --datasets openlifescienceai/pubmedqa
With multiple datasets:
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa,openlifescienceai/mmlu_professional_medicine
With custom arguments:
karma eval --model "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa \
--model-args '{"temperature": 0.8, "top_p": 0.85}'
--max-samples 100 --batch-size 4
Interactive mode:
karma eval --model "Qwen/Qwen3-0.6B" --interactive
✓ Model information retrieved successfully
```
# Model Configuration
Learn how to configure and customize models for optimal performance in medical AI evaluation. The loader\_args that are defined on the ModelMeta can be tweaked
## Parameter Tuning
[Section titled “Parameter Tuning”](#parameter-tuning)
### Generation Parameters
[Section titled “Generation Parameters”](#generation-parameters)
Control model behavior with precision:
```bash
# Conservative generation for medical accuracy
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa \
--model-kwargs '{
"temperature": 0.1,
"top_p": 0.9,
"top_k": 50,
"max_tokens": 512,
"enable_thinking": true,
"seed": 42
}'
# Creative generation for medical education
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets medical_education_dataset \
--model-kwargs '{
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 1024,
"enable_thinking": false
}'
```
### Parameter Reference
[Section titled “Parameter Reference”](#parameter-reference)
| Parameter | Range | Description | Medical Use Case |
| ----------------- | ------- | ------------------ | ------------------------------- |
| `temperature` | 0.0-1.0 | Randomness control | 0.1-0.3 for diagnostic accuracy |
| `top_p` | 0.0-1.0 | Nucleus sampling | 0.9 for balanced responses |
| `top_k` | 1-100 | Top-k sampling | 50 for medical terminology |
| `max_tokens` | 1-4096 | Output length | 512 for concise answers |
| `enable_thinking` | boolean | Reasoning mode | true for complex cases |
| `seed` | integer | Reproducibility | Set for consistent results |
## Model-Specific Configuration
[Section titled “Model-Specific Configuration”](#model-specific-configuration)
### Qwen Models
[Section titled “Qwen Models”](#qwen-models)
```bash
# Thinking mode for complex medical reasoning
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa \
--model-kwargs '{
"enable_thinking": true,
"thinking_depth": 3,
"temperature": 0.2,
"max_tokens": 512
}'
# Fast inference mode
karma eval --model qwen --model-path "Qwen/Qwen3-0.6B" \
--datasets openlifescienceai/pubmedqa \
--model-kwargs '{
"enable_thinking": false,
"temperature": 0.1,
"max_tokens": 256,
"use_cache": true
}'
```
### MedGemma Models
[Section titled “MedGemma Models”](#medgemma-models)
```bash
# Medical accuracy optimization
karma eval --model medgemma --model-path "google/medgemma-4b-it" \
--datasets openlifescienceai/medmcqa \
--model-kwargs '{
"temperature": 0.05,
"top_p": 0.8,
"repetition_penalty": 1.1,
"max_tokens": 400,
"medical_mode": true
}'
```
### Audio Models
[Section titled “Audio Models”](#audio-models)
```bash
# IndicConformer language-specific configuration
karma eval --model "ai4bharat/indic-conformer-600m-multilingual" \
--model-path "ai4bharat/indic-conformer-600m-multilingual" \
--datasets "ai4bharat/indicvoices_r" \
--model-kwargs '{
"language": "Hindi",
"chunk_length": 30,
"stride": 5,
"batch_size": 1,
"use_lm": true
}'
# Whisper optimization
karma eval --model openai-whisper \
--datasets medical_audio_dataset \
--model-kwargs '{
"model": "whisper-1",
"language": "en",
"temperature": 0.0,
"condition_on_previous_text": true,
"compression_ratio_threshold": 2.4
}'
```
# Processors Guide
Processors run on the output of the model and used to perform some normalisation or similar operations before computing the metrics. They are registered in the dataset along with the metrics. Processors output is piped from the previous processor to the next.
## Quick Start
[Section titled “Quick Start”](#quick-start)
```bash
# Use processor with evaluation
karma eval --model "ai4bharat/indic-conformer-600m-multilingual" \
--datasets "ai4bharat/IN22-Conv" \
--processor-args "ai4bharat/IN22-Conv.devnagari_transliterator:source_script=en,target_script=hi"
```
## Architecture
[Section titled “Architecture”](#architecture)
The processor system consists of:
* **Base Processor**: `BaseProcessor` class that all processors inherit from
* **Processor Registry**: Auto-discovery system that finds and registers processors
* **Integration Points**: Processors can be applied at dataset level or via CLI
Processors are defined with the datasets in the decorator. The processors are by default chained i.e., the output of the previous processor is the input of the next processor.
## Available Processors
[Section titled “Available Processors”](#available-processors)
**GeneralTextProcessor**
* Handles common text normalization
* Number to text conversion
* Punctuation removal
* Case normalization
**DevanagariTransliterator**
* Multilingual text processing for indic Devanagri scripts
* Script conversion between languages
* Handles Devanagari text
**MultilingualTextProcessor**
* Audio transcription normalization
* Specialized for STT tasks where numbers need to be normalized
# Registry System Deep Dive
Registries are the backbone of KARMA’s component discovery and management system. They provide a sophisticated, decorator-based mechanism for automatically discovering and utilizing core components including models, datasets, metrics, and processors. This system is designed for high performance with caching, parallel discovery, and thread-safety.
## Architecture Overview
[Section titled “Architecture Overview”](#architecture-overview)
### Core Components
[Section titled “Core Components”](#core-components)
The registry system consists of several key components working together:
1. **Registry Manager** (`karma/registries/registry_manager.py`) - Orchestrates discovery across all registries
2. **Individual Registries** - Specialized registries for each component type
3. **CLI Integration** - Seamless command-line interface integration
## Component Registration
[Section titled “Component Registration”](#component-registration)
### Models
[Section titled “Models”](#models)
Models are registered using `ModelMeta` objects that provide comprehensive metadata. The model registry supports multi-modal models and various frameworks.
**Key Features:**
* **ModelMeta System**: Pydantic-based configuration with type validation
* **Multi-modal Support**: Handles text, audio, image, video modalities
* **Type Classification**: Categorizes models by type (text\_generation, audio\_recognition, etc.)
* **Loader Configuration**: Flexible model loading with parameter overrides
**Registration Example:**
```python
from karma.registries.model_registry import register_model_meta, ModelMeta
from karma.core.model_meta import ModelType, ModalityType
# Define model metadata
QwenModel = ModelMeta(
name="Qwen/Qwen3-0.6B",
description="QWEN model for text generation",
loader_class="karma.models.qwen.QwenThinkingLLM",
loader_kwargs={
"temperature": 0.7,
"top_k": 50,
"top_p": 0.9,
"enable_thinking": True,
"max_tokens": 32768,
},
model_type=ModelType.TEXT_GENERATION,
modalities=[ModalityType.TEXT],
framework=["PyTorch", "Transformers"],
)
# Register the model
register_model_meta(QwenModel)
```
### Datasets
[Section titled “Datasets”](#datasets)
Datasets are registered using decorators that specify comprehensive metadata including supported metrics and task types.
**Key Features:**
* **Metric Association**: Links datasets to supported metrics
* **Task Type Classification**: Categorizes by task (mcqa, vqa, translation, etc.)
* **Argument Validation**: Validates required/optional arguments
* **HuggingFace Integration**: Supports commit hashes and splits
**Registration Example:**
```python
from karma.registries.dataset_registry import register_dataset
from karma.datasets.base_multimodal_dataset import BaseMultimodalDataset
@register_dataset(
"openlifescienceai/medqa",
commit_hash="153e61cdd129eb79d3c27f82cdf3bc5e018c11b0",
split="test",
metrics=["exact_match"],
task_type="mcqa",
required_args=["num_choices"],
optional_args=["language", "subset"],
default_args={"num_choices": 4, "language": "en"}
)
class MedQADataset(BaseMultimodalDataset):
"""Medical Question Answering dataset."""
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Dataset-specific initialization
def load_data(self):
# Implementation for loading dataset
pass
```
See more at **[Datasets](/user-guide/datasets/datasets_overview/)**
### Metrics
[Section titled “Metrics”](#metrics)
The metrics registry supports both KARMA-native metrics and HuggingFace Evaluate metrics with automatic fallback.
**Key Features:**
* **Dual Support**: Native metrics and HuggingFace Evaluate library fallback
* **Argument Validation**: Validates metric parameters
* **Dynamic Loading**: Lazy loading of HuggingFace metrics
**Registration Example:**
```python
from karma.registries.metrics_registry import register_metric
from karma.metrics.hf_metric import HfMetric
@register_metric(
"exact_match",
optional_args=["ignore_case", "normalize_text"],
default_args={"ignore_case": True, "normalize_text": False}
)
class ExactMatchMetric(HfMetric):
"""Exact match metric with case sensitivity options."""
def __init__(self, **kwargs):
super().__init__(**kwargs)
def compute(self, predictions, references):
# Implementation for exact match computation
pass
```
### Processors
[Section titled “Processors”](#processors)
Processors handle text and data transformation with flexible argument validation.
**Key Features:**
* **Text Processing**: Supports transliteration, normalization, etc.
* **Argument Validation**: Validates processor parameters
* **Modular Design**: Easy to extend with new processors
**Registration Example:**
```python
from karma.registries.processor_registry import register_processor
from karma.processors.base_processor import BaseProcessor
@register_processor(
"devnagari_transliterator",
optional_args=["normalize", "fallback_scheme"],
default_args={"normalize": True, "fallback_scheme": None}
)
class DevanagariTransliterator(BaseProcessor):
"""Transliterator for Devanagari script."""
def __init__(self, **kwargs):
super().__init__(**kwargs)
def process(self, text):
# Implementation for transliteration
pass
```
## CLI Integration
[Section titled “CLI Integration”](#cli-integration)
The registry system seamlessly integrates with the CLI for component discovery and listing.
### Discovery Commands
[Section titled “Discovery Commands”](#discovery-commands)
```bash
# List all models
karma list models
# List datasets with filtering
karma list datasets --task-type mcqa --metric accuracy
# List all metrics
karma list metrics
# List all processors
karma list processors
# List all components
karma list all
```
### Error Handling
[Section titled “Error Handling”](#error-handling)
The registry system provides robust error handling:
* **Graceful Degradation**: Individual registry failures don’t break the system
* **Fallback Mechanisms**: HuggingFace metrics as fallback for missing metrics
* **Validation**: Comprehensive argument validation with helpful error messages
* **Logging**: Detailed logging for debugging and monitoring
## Best Practices
[Section titled “Best Practices”](#best-practices)
1. **Use Descriptive Names**: Choose clear, descriptive names for your components
2. **Provide Comprehensive Metadata**: Include detailed descriptions and argument specifications
3. **Validate Arguments**: Implement proper argument validation in your components
4. **Follow Naming Conventions**: Use consistent naming patterns across your components
5. **Document Dependencies**: Clearly specify framework and library requirements
6. **Test Registration**: Verify your components are properly registered and discoverable
## File Structure
[Section titled “File Structure”](#file-structure)
The registry system is organized across several key files:
```plaintext
karma/registries/
├── registry_manager.py # Central registry coordination
├── model_registry.py # Model registration and discovery
├── dataset_registry.py # Dataset registration and discovery
├── metrics_registry.py # Metrics registration and discovery
├── processor_registry.py # Processor registration and discovery
└── cache_manager.py # Caching system implementation
```
This registry system provides a highly scalable, performant, and user-friendly way to manage and discover components in the KARMA framework, with particular emphasis on medical AI evaluation tasks.
# Running evaluations
This guide covers the fundamental usage patterns of KARMA for medical AI evaluation.
### Evaluate Specific Datasets
[Section titled “Evaluate Specific Datasets”](#evaluate-specific-datasets)
```bash
# Single dataset
karma eval --model Qwen/Qwen3-0.6B --datasets openlifescienceai/pubmedqa
# Multiple datasets
karma eval --model Qwen/Qwen3-0.6B --datasets "openlifescienceai/pubmedqa,openlifescienceai/medmcqa,openlifescienceai/medqa"
```
### Save Results
[Section titled “Save Results”](#save-results)
```bash
# Save to JSON file
karma eval --model Qwen/Qwen3-0.6B --output results.json
# Save to custom path
karma eval --model Qwen/Qwen3-0.6B --output /path/to/results.json
```
## Working with Different Models
[Section titled “Working with Different Models”](#working-with-different-models)
### Built-in Models
[Section titled “Built-in Models”](#built-in-models)
KARMA includes several pre-configured models:
```bash
# Qwen models
karma eval --model Qwen/Qwen3-0.6B
karma eval --model Qwen/Qwen3-0.6B --model-path "Qwen/Qwen3-1.7B"
# MedGemma models
karma eval --model medgemma --model-path "google/medgemma-4b-it"
```
### Custom Model Parameters
[Section titled “Custom Model Parameters”](#custom-model-parameters)
```bash
# Adjust generation parameters
karma eval --model Qwen/Qwen3-0.6B \
--model-args '{"temperature":0.5,"max_tokens":512,"top_p":0.9}'
# Disable thinking mode (for Qwen)
karma eval --model Qwen/Qwen3-0.6B \
--model-args '{"enable_thinking":false}'
```
## Dataset Configuration
[Section titled “Dataset Configuration”](#dataset-configuration)
### Dataset-Specific Arguments
[Section titled “Dataset-Specific Arguments”](#dataset-specific-arguments)
Some datasets require additional configuration:
```bash
# Translation datasets with language pairs
karma eval --model Qwen/Qwen3-0.6B \
--datasets "ai4bharat/IN22-Conv" \
--dataset-args "ai4bharat/IN22-Conv:source_language=en,target_language=hi"
# Datasets with specific splits
karma eval --model Qwen/Qwen3-0.6B --datasets "openlifescienceai/medmcqa" \
--dataset-args "openlifescienceai/medmcqa:split=validation"
```
## Performance Optimization
[Section titled “Performance Optimization”](#performance-optimization)
### Batch Processing
[Section titled “Batch Processing”](#batch-processing)
```bash
# Adjust batch size for your hardware
karma eval --model Qwen/Qwen3-0.6B --batch-size 8
# Smaller batch for limited memory
karma eval --model Qwen/Qwen3-0.6B --batch-size 2
# Larger batch for high-end hardware
karma eval --model Qwen/Qwen3-0.6B --batch-size 16
```
### Caching
[Section titled “Caching”](#caching)
KARMA uses intelligent caching to speed up repeated evaluations:
```bash
# Use cache (default)
karma eval --model Qwen/Qwen3-0.6B --cache
# Force fresh evaluation
karma eval --model Qwen/Qwen3-0.6B --no-cache
# Refresh cache
karma eval --model Qwen/Qwen3-0.6B --refresh-cache
```
## Understanding Results
[Section titled “Understanding Results”](#understanding-results)
### Result Format
[Section titled “Result Format”](#result-format)
KARMA outputs comprehensive evaluation results:
```json
{
"model": "qwen",
"model_path": "Qwen/Qwen3-0.6B",
"results": {
"openlifescienceai/pubmedqa": {
"metrics": {
"exact_match": 0.745,
"accuracy": 0.745
},
"num_examples": 1000,
"runtime_seconds": 45.2,
"cache_hit_rate": 0.8
},
"openlifescienceai/medmcqa": {
"metrics": {
"exact_match": 0.623,
"accuracy": 0.623
},
"num_examples": 4183,
"runtime_seconds": 120.5,
"cache_hit_rate": 0.2
}
},
"total_runtime": 165.7,
"timestamp": "2025-01-15T10:30:00Z"
}
```
## Common Workflows
[Section titled “Common Workflows”](#common-workflows)
### Model Comparison
[Section titled “Model Comparison”](#model-comparison)
```bash
# Compare different model sizes
karma eval --model Qwen/Qwen3-0.6B --output qwen_0.6b.json
karma eval --model "Qwen/Qwen3-1.7B" --output qwen_1.7b.json
# Compare different models
karma eval --model Qwen/Qwen3-0.6B --output qwen_results.json
karma eval --model "google/medgemma-4b-it" --output medgemma_results.json
```
### Dataset-Specific Evaluation
[Section titled “Dataset-Specific Evaluation”](#dataset-specific-evaluation)
```bash
# Focus on specific medical domains
karma eval --model Qwen/Qwen3-0.6B \
--datasets "openlifescienceai/pubmedqa,openlifescienceai/medmcqa,openlifescienceai/medqa" # Text-based QA
karma eval --model Qwen/Qwen3-0.6B \
--datasets "mdwiratathya/SLAKE-vqa-english,flaviagiammarino/vqa-rad" # Vision-language tasks
```
### Parameter Tuning
[Section titled “Parameter Tuning”](#parameter-tuning)
```bash
# Test different temperature settings
karma eval --model Qwen/Qwen3-0.6B \
--model-args '{"temperature":0.1}' --output temp_0.1.json
karma eval --model Qwen/Qwen3-0.6B \
--model-args '{"temperature":0.7}' --output temp_0.7.json
karma eval --model Qwen/Qwen3-0.6B \
--model-args '{"temperature":1.0}' --output temp_1.0.json
```
# Using KARMA as a package
KARMA provides both a CLI interface and a Python API for programmatic use. This guide walks you through building an evaluation pipeline using the API.
## Overview
[Section titled “Overview”](#overview)
The KARMA API centers around the `Benchmark` class, which coordinates models, datasets, metrics, and caching. Here’s how to build a complete evaluation pipeline.
Let’s work with an example that uses all the core components of KARMA: Models, Datasets, Metrics, and Processors.
Here we are trying to evaluate `IndicVoicesRDataset`, an ASR dataset for evaluating speech recognition models. We will be using the `IndicConformerASR` model and the `WERMetric` and `CERMetric` metrics. Before passing to the metrics, the model’s output will be passed to the processors, which will perform text normalization and tokenization.
## Essential Imports
[Section titled “Essential Imports”](#essential-imports)
Start with the core components:
```python
import sys
import os
# Core KARMA components
from karma.benchmark import Benchmark
from karma.cache.cache_manager import CacheManager
# Model components
from karma.models.indic_conformer import IndicConformerASR, INDIC_CONFORMER_MULTILINGUAL_META
# Dataset components
from karma.eval_datasets.indicvoices_r_dataset import IndicVoicesRDataset
# Metrics components
from karma.metrics.common_metrics import WERMetric, CERMetric
# Processing components
from karma.processors.multilingual_text_processor import MultilingualTextProcessor
```
Here’s what each import does:
* `Benchmark`: Orchestrates the entire evaluation process
* `CacheManager`: Caches model predictions to avoid redundant computations
* `IndicConformerASR`: An Indic language speech recognition model
* `INDIC_CONFORMER_MULTILINGUAL_META`: Model metadata for caching
* `IndicVoicesRDataset`: Speech recognition dataset for evaluation
* `WERMetric`/`CERMetric`: Word and character error rate metrics
* `MultilingualTextProcessor`: Normalizes text for consistent comparison
## Complete Example
[Section titled “Complete Example”](#complete-example)
Here’s a working example that evaluates a speech recognition model:
```python
def main():
# Initialize the model
print("Initializing model...")
model = IndicConformerASR(model_name_or_path="ai4bharat/indic-conformer-600m-multilingual")
# Set up text processing
processor = MultilingualTextProcessor()
# Create the dataset
print("Loading dataset...")
dataset = IndicVoicesRDataset(
language="Hindi",
postprocessors=[processor]
)
# Configure metrics
metric_configs = [
{
"metric": WERMetric(metric_name="wer"),
"processors": []
},
{
"metric": CERMetric(metric_name="cer"),
"processors": []
}
]
# Set up caching
cache_manager = CacheManager(
model_config=INDIC_CONFORMER_MULTILINGUAL_META,
dataset_name=dataset.dataset_name
)
# Create and run benchmark
benchmark = Benchmark(
model=model,
dataset=dataset,
cache_manager=cache_manager
)
print("Running evaluation...")
results = benchmark.evaluate(
metric_configs=metric_configs,
batch_size=1
)
# Display results
print(f"Word Error Rate (WER): {results['overall_score']['wer']:.4f}")
print(f"Character Error Rate (CER): {results['overall_score']['cer']:.4f}")
return results
if __name__ == "__main__":
main()
```
## Understanding the Flow
[Section titled “Understanding the Flow”](#understanding-the-flow)
When you run this code, here’s what happens:
1. **Model Initialization**: Creates an instance of the speech recognition model and loads pretrained weights
2. **Text Processing**: Sets up text normalization to ensure fair comparison between predictions and ground truth
3. **Dataset Creation**: Loads Hindi speech samples with their transcriptions and applies text processing
4. **Metrics Configuration**: Defines WER (word-level errors) and CER (character-level errors) metrics
5. **Cache Setup**: Creates a cache manager to store predictions and avoid recomputation
6. **Evaluation**: The benchmark iterates through samples, runs inference, and computes metrics
## Advanced Usage
[Section titled “Advanced Usage”](#advanced-usage)
### Batch Processing
[Section titled “Batch Processing”](#batch-processing)
```python
# Process multiple samples at once for better performance
results = benchmark.evaluate(
metric_configs=metric_configs,
batch_size=8,
max_samples=100
)
```
### Custom Metrics
[Section titled “Custom Metrics”](#custom-metrics)
```python
from karma.metrics.base_metric import BaseMetric
class CustomAccuracyMetric(BaseMetric):
def __init__(self, metric_name="custom_accuracy"):
super().__init__(metric_name)
def evaluate(self, predictions, references, **kwargs):
correct = sum(1 for p, r in zip(predictions, references) if p.strip() == r.strip())
return correct / len(predictions)
metric_configs = [{"metric": CustomAccuracyMetric(), "processors": []}]
```
### Multiple Languages
[Section titled “Multiple Languages”](#multiple-languages)
```python
languages = ["Hindi", "Telugu", "Tamil"]
results_by_language = {}
for language in languages:
dataset = IndicVoicesRDataset(language=language, postprocessors=[processor])
benchmark = Benchmark(model=model, dataset=dataset, cache_manager=cache_manager)
results_by_language[language] = benchmark.evaluate(metric_configs=metric_configs)
```
### Multiple Datasets
[Section titled “Multiple Datasets”](#multiple-datasets)
The user is responsible for creating the multiple dataset objects while using multiple datasets.
```python
# Both these datasets are for ASR
dataset_1 = IndicVoicesRDataset(language=language, postprocessors=[processor])
dataset_2 = IndicVoicesDataset(language=language, postprocessors=[processor])
dataset_results = []
for i in [dataset_1, dataset_2]:
benchmark = Benchmark(model=model, dataset=dataset, cache_manager=cache_manager)
dataset_results[i.name] = benchmark.evaluate(metric_configs=metric_configs)
```
### Progress Tracking
[Section titled “Progress Tracking”](#progress-tracking)
```python
from rich.progress import Progress
with Progress() as progress:
benchmark = Benchmark(
model=model,
dataset=dataset,
cache_manager=cache_manager,
progress=progress
)
results = benchmark.evaluate(metric_configs=metric_configs, batch_size=1)
```
This API gives you complete control over your evaluation pipeline while maintaining KARMA’s performance optimizations and robustness.